<h1><b>Highlights:</a></b></h1>
* Merge pre-trained BERTopic models with [**`.merge_models`**](https://maartengr.github.io/BERTopic/getting_started/merge/merge.html)
* Combine models with different representations together!
* Use this for *incremental/online topic modeling* to detect new incoming topics
* First step towards *federated learning* with BERTopic
* [**Zero-shot**](https://maartengr.github.io/BERTopic/getting_started/zeroshot/zeroshot.html) Topic Modeling
* Use a predefined list of topics to assign documents
* If needed, allows for further exploration of undefined topics
* [**Seed (domain-specific) words**](https://maartengr.github.io/BERTopic/getting_started/seed_words/seed_words.html) with `ClassTfidfTransformer`
* Make sure selected words are more likely to end up in the representation without influencing the clustering process
* Added params to [**truncate documents**](https://maartengr.github.io/BERTopic/getting_started/representation/llm.html#truncating-documents) to length when using LLMs
* Added [**LlamaCPP**](https://maartengr.github.io/BERTopic/getting_started/representation/llm.html#llamacpp) as a representation model
* LangChain: Support for **LCEL Runnables** by [joshuasundance-swca](https://github.com/joshuasundance-swca) in [#1586](https://github.com/MaartenGr/BERTopic/pull/1586)
* Added `topics` parameter to `.topics_over_time` to select a subset of documents and topics
* Documentation:
* [Best practices Guide](https://maartengr.github.io/BERTopic/getting_started/best_practices/best_practices.html)
* [Llama 2 Tutorial](https://maartengr.github.io/BERTopic/getting_started/representation/llm.html#llama-2)
* [Zephyr Tutorial](https://maartengr.github.io/BERTopic/getting_started/representation/llm.html#zephyr-mistral-7b)
* Improved [embeddings guidance](https://maartengr.github.io/BERTopic/getting_started/embeddings/embeddings.html#sentence-transformers) (MTEB)
* Improved logging throughout the package
* Added support for **Cohere's Embed v3**:
python
cohere_model = CohereBackend(
client,
embedding_model="embed-english-v3.0",
embed_kwargs={"input_type": "clustering"}
)
<h1><b>Fixes:</a></b></h1>
* Fixed n-gram Keywords need delimiting in OpenAI() [1546](https://github.com/MaartenGr/BERTopic/issues/1546)
* Fixed OpenAI v1.0 issues [1629](https://github.com/MaartenGr/BERTopic/issues/1629)
* Improved documentation/logging to adress [1589](https://github.com/MaartenGr/BERTopic/issues/1589), [#1591](https://github.com/MaartenGr/BERTopic/issues/1591)
* Fixed engine support for Azure OpenAI embeddings [1577](https://github.com/MaartenGr/BERTopic/issues/1487)
* Fixed OpenAI Representation: KeyError: 'content' [1570](https://github.com/MaartenGr/BERTopic/issues/1570)
* Fixed Loading topic model with multiple topic aspects changes their format [1487](https://github.com/MaartenGr/BERTopic/issues/1487)
* Fix expired link in algorithm.md by [burugaria7](https://github.com/burugaria7) in [#1396](https://github.com/MaartenGr/BERTopic/pull/1396)
* Fix guided topic modeling in cuML's UMAP by [stevetracvc](https://github.com/stevetracvc) in [#1326](https://github.com/MaartenGr/BERTopic/pull/1326)
* OpenAI: Allow retrying on Service Unavailable errors by [agamble](https://github.com/agamble) in [#1407](https://github.com/MaartenGr/BERTopic/pull/1407)
* Fixed parameter naming for HDBSCAN in best practices by [rnckp](https://github.com/rnckp) in [#1408](https://github.com/MaartenGr/BERTopic/pull/1408)
* Fixed typo in tips_and_tricks.md by [aronnoordhoek](https://github.com/aronnoordhoek) in [#1446](https://github.com/MaartenGr/BERTopic/pull/1446)
* Fix typos in documentation by [bobchien](https://github.com/bobchien) in [#1481](https://github.com/MaartenGr/BERTopic/pull/1481)
* Fix IndexError when all outliers are removed by reduce_outliers by [Aratako](https://github.com/Aratako) in [#1466](https://github.com/MaartenGr/BERTopic/pull/1466)
* Fix TypeError on reduce_outliers "probabilities" by [ananaphasia](https://github.com/ananaphasia) in [#1501](https://github.com/MaartenGr/BERTopic/pull/1501)
* Add new line to fix markdown bullet point formatting by [saeedesmaili](https://github.com/saeedesmaili) in [#1519](https://github.com/MaartenGr/BERTopic/pull/1519)
* Update typo in topicrepresentation.md by [oliviercaron](https://github.com/oliviercaron) in [#1537](https://github.com/MaartenGr/BERTopic/pull/1537)
* Fix typo in FAQ by [sandijou](https://github.com/sandijou) in [#1542](https://github.com/MaartenGr/BERTopic/pull/1542)
* Fixed typos in best practices documentation by [poomkusa](https://github.com/poomkusa) in [#1557](https://github.com/MaartenGr/BERTopic/pull/1557)
* Correct TopicMapper doc example by [chrisji](https://github.com/chrisji) in [#1637](https://github.com/MaartenGr/BERTopic/pull/1637)
* Fix typing in hierarchical_topics by [dschwalm](https://github.com/dschwalm) in [#1364](https://github.com/MaartenGr/BERTopic/pull/1364)
* Fixed typing issue with treshold parameter in reduce_outliers by [dschwalm](https://github.com/dschwalm) in [#1380](https://github.com/MaartenGr/BERTopic/pull/1380)
* Fix several typos by [mertyyanik](https://github.com/mertyyanik) in [#1307](https://github.com/MaartenGr/BERTopic/pull/1307)
(1307)
* Fix inconsistent naming by [rolanderdei](https://github.com/rolanderdei) in [#1073](https://github.com/MaartenGr/BERTopic/pull/1073)
<h1><b><a href="https://maartengr.github.io/BERTopic/getting_started/merge/merge.html">Merge Pre-trained BERTopic Models</a></b></h1>
The new `.merge_models` feature allows for any number of fitted BERTopic models to be merged. Doing so allows for a number of use cases:
* **Incremental topic modeling** -- Continuously merge models together to detect whether new topics have appeared
* **Federated Learning** - Train BERTopic models on different clients and combine them on a central server
* **Minimal compute** - We can essentially batch the training process into multiple instances to reduce compute
* **Different datasets** - When you have different datasets that you want to train seperately on, for example with different languages, you can train each model separately and join them after training
To demonstrate merging different topic models with BERTopic, we use the ArXiv paper abstracts to see which topics they generally contain.
First, we train three separate models on different parts of the data:
python
from umap import UMAP
from bertopic import BERTopic
from datasets import load_dataset
dataset = load_dataset("CShorten/ML-ArXiv-Papers")["train"]
Extract abstracts to train on and corresponding titles
abstracts_1 = dataset["abstract"][:5_000]
abstracts_2 = dataset["abstract"][5_000:10_000]
abstracts_3 = dataset["abstract"][10_000:15_000]
Create topic models
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine', random_state=42)
topic_model_1 = BERTopic(umap_model=umap_model, min_topic_size=20).fit(abstracts_1)
topic_model_2 = BERTopic(umap_model=umap_model, min_topic_size=20).fit(abstracts_2)
topic_model_3 = BERTopic(umap_model=umap_model, min_topic_size=20).fit(abstracts_3)
Then, we can combine all three models into one with `.merge_models`:
python
Combine all models into one
merged_model = BERTopic.merge_models([topic_model_1, topic_model_2, topic_model_3])
<h1><b><a href="https://maartengr.github.io/BERTopic/getting_started/zeroshot/zeroshot.html">Zero-shot Topic Modeling</a></b></h1>
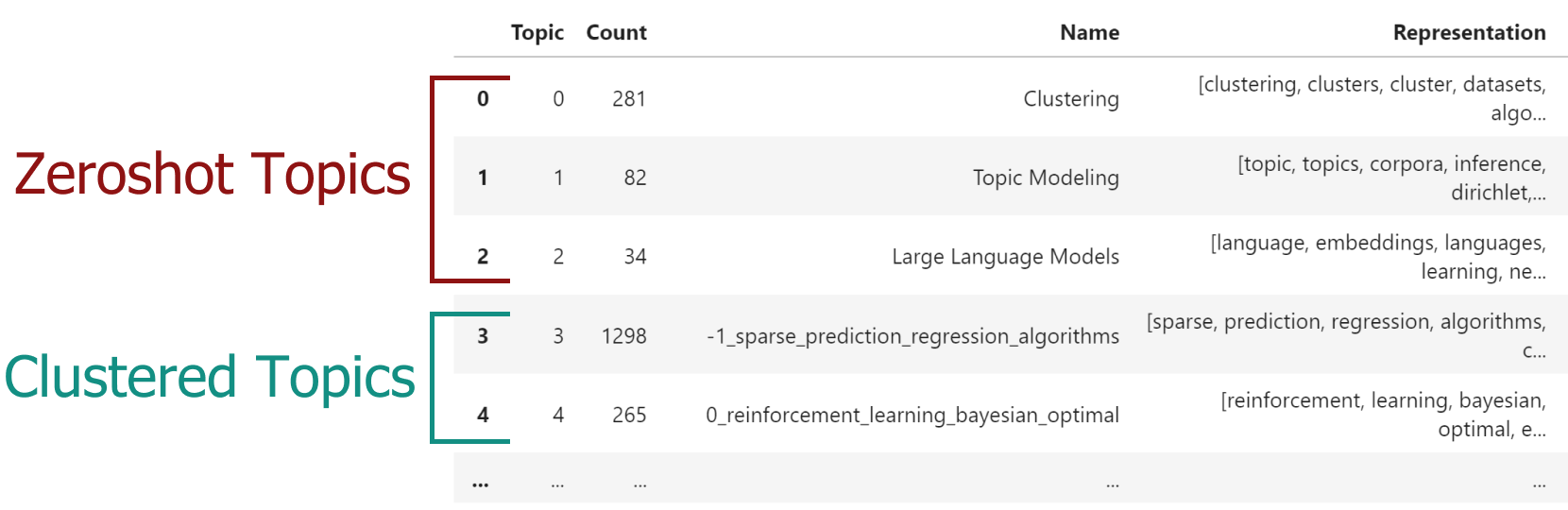
Zeroshot Topic Modeling is a technique that allows you to find pre-defined topics in large amounts of documents. This method allows you to not only find those specific topics but also create new topics for documents that would not fit with your predefined topics.
This allows for extensive flexibility as there are three scenario's to explore.
* No zeroshot topics were detected. This means that none of the documents would fit with the predefined topics and a regular BERTopic would be run.
* Only zeroshot topics were detected. Here, we would not need to find additional topics since all original documents were assigned to one of the predefined topics.
* Both zeroshot topics and clustered topics were detected. This means that some documents would fit with the predefined topics where others would not. For the latter, new topics were found.

In order to use zero-shot BERTopic, we create a list of topics that we want to assign to our documents. However,
there may be several other topics that we know should be in the documents. The dataset that we use is small subset of ArXiv papers.
We know the data and believe there to be at least the following topics: *clustering*, *topic modeling*, and *large language models*.
However, we are not sure whether other topics exist and want to explore those.
Using this feature is straightforward:
python
from datasets import load_dataset
from bertopic import BERTopic
from bertopic.representation import KeyBERTInspired
We select a subsample of 5000 abstracts from ArXiv
dataset = load_dataset("CShorten/ML-ArXiv-Papers")["train"]
docs = dataset["abstract"][:5_000]
We define a number of topics that we know are in the documents
zeroshot_topic_list = ["Clustering", "Topic Modeling", "Large Language Models"]
We fit our model using the zero-shot topics
and we define a minimum similarity. For each document,
if the similarity does not exceed that value, it will be used
for clustering instead.
topic_model = BERTopic(
embedding_model="thenlper/gte-small",
min_topic_size=15,
zeroshot_topic_list=zeroshot_topic_list,
zeroshot_min_similarity=.85,
representation_model=KeyBERTInspired()
)
topics, _ = topic_model.fit_transform(docs)
When we run `topic_model.get_topic_info()` you will see something like this:
<h1><b><a href="https://maartengr.github.io/BERTopic/getting_started/seed_words/seed_words.html">Seed (Domain-specific) Words</a></b></h1>
When performing Topic Modeling, you are often faced with data that you are familiar with to a certain extend or that speaks a very specific language. In those cases, topic modeling techniques might have difficulties capturing and representing the semantic nature of domain specific abbreviations, slang, short form, acronyms, etc. For example, the *"TNM"* classification is a method for identifying the stage of most cancers. The word *"TNM"* is an abbreviation and might not be correctly captured in generic embedding models.
To make sure that certain domain specific words are weighted higher and are more often used in topic representations, you can set any number of `seed_words` in the `bertopic.vectorizer.ClassTfidfTransformer`. To do so, let's take a look at an example. We have a dataset of article abstracts and want to perform some topic modeling. Since we might be familiar with the data, there are certain words that we know should be generally important. Let's assume that we have in-depth knowledge about reinforcement learning and know that words like "agent" and "robot" should be important in such a topic were it to be found. Using the `ClassTfidfTransformer`, we can define those `seed_words` and also choose by how much their values are multiplied.
The full example is then as follows:
python
from umap import UMAP
from datasets import load_dataset
from bertopic import BERTopic
from bertopic.vectorizers import ClassTfidfTransformer
Let's take a subset of ArXiv abstracts as the training data
dataset = load_dataset("CShorten/ML-ArXiv-Papers")["train"]
abstracts = dataset["abstract"][:5_000]
For illustration purposes, we make sure the output is fixed when running this code multiple times
umap_model = UMAP(n_neighbors=15, n_components=5, min_dist=0.0, metric='cosine', random_state=42)
We can choose any number of seed words for which we want their representation
to be strengthen. We increase the importance of these words as we want them to be more
likely to end up in the topic representations.
ctfidf_model = ClassTfidfTransformer(
seed_words=["agent", "robot", "behavior", "policies", "environment"],
seed_multiplier=2
)
We run the topic model with the seeded words
topic_model = BERTopic(
umap_model=umap_model,
min_topic_size=15,
ctfidf_model=ctfidf_model,
).fit(abstracts)
<h1><b><a href="https://maartengr.github.io/BERTopic/getting_started/representation/llm.html#truncating-documents">Truncate Documents in LLMs</a></b></h1>
When using LLMs with BERTopic, we can truncate the input documents in `[DOCUMENTS]` in order to reduce the number of tokens that we have in our input prompt. To do so, all text generation modules have two parameters that we can tweak:
* `doc_length` - The maximum length of each document. If a document is longer, it will be truncated. If None, the entire document is passed.
* `tokenizer` - The tokenizer used to calculate to split the document into segments used to count the length of a document.
* Options include `'char'`, `'whitespace'`, `'vectorizer'`, and a callable
This means that the definition of `doc_length` changes depending on what constitutes a token in the `tokenizer` parameter. If a token is a character, then `doc_length` refers to max length in characters. If a token is a word, then `doc_length` refers to the max length in words.
Let's illustrate this with an example. In the code below, we will use [`tiktoken`](https://github.com/openai/tiktoken) to count the number of tokens in each document and limit them to 100 tokens. All documents that have more than 100 tokens will be truncated.
We use `bertopic.representation.OpenAI` to represent our topics with nicely written labels. We specify that documents that we put in the prompt cannot exceed 100 tokens each. Since we will put 4 documents in the prompt, they will total roughly 400 tokens:
python
import openai
import tiktoken
from bertopic.representation import OpenAI
from bertopic import BERTopic
Tokenizer
tokenizer= tiktoken.encoding_for_model("gpt-3.5-turbo")
Create your representation model
openai.api_key = MY_API_KEY
client = openai.OpenAI(api_key="sk-...")
representation_model = OpenAI(
client,
model="gpt-3.5-turbo",
delay_in_seconds=2,
chat=True,
nr_docs=4,
doc_length=100,
tokenizer=tokenizer
)
Use the representation model in BERTopic on top of the default pipeline
topic_model = BERTopic(representation_model=representation_model)