Phi-3-MLX is a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the Phi-3-Mini-128K language model, optimized for Apple Silicon using the MLX framework. This project provides an easy-to-use interface for a wide range of AI tasks, from advanced text generation to visual question answering and code execution.
Features
- Integration with Phi-3-Vision (multimodal) model
- Support for the Phi-3-Mini-128K (language-only) model
- Optimized performance on Apple Silicon using MLX
- Batched generation for processing multiple prompts
- Flexible agent system for various AI tasks
- Custom toolchains for specialized workflows
- Model quantization for improved efficiency
- LoRA fine-tuning capabilities
- API integration for extended functionality (e.g., image generation, text-to-speech)
Quick Start
Install and launch Phi-3-MLX from command line:
bash
pip install phi-3-vision-mlx
phi3v
To instead use the library in a Python script:
python
from phi_3_vision_mlx import generate
1. Core Functionalities
Visual Question Answering
python
generate('What is shown in this image?', 'https://collectionapi.metmuseum.org/api/collection/v1/iiif/344291/725918/main-image')
Batch Text Generation
python
A list of prompts for batch generation
prompts = [
"Explain the key concepts of quantum computing and provide a Rust code example demonstrating quantum superposition.",
"Write a poem about the first snowfall of the year.",
"Summarize the major events of the French Revolution.",
"Describe a bustling alien marketplace on a distant planet with unique goods and creatures."
"Implement a basic encryption algorithm in Python.",
]
Generate responses using Phi-3-Vision (multimodal model)
generate(prompts, max_tokens=100)
Generate responses using Phi-3-Mini-128K (language-only model)
generate(prompts, max_tokens=100, blind_model=True)
Constrained (Beam Search) Decoding
The `constrain` function allows for structured generation, which can be useful for tasks like code generation, function calling, chain-of-thought prompting, or multiple-choice question answering.
python
from phi_3_vision_mlx import constrain
Define the prompt
prompt = "Write a Python function to calculate the Fibonacci sequence up to a given number n."
Define constraints
constraints = [
(100, "\npython\n"), Start of code block
(100, " return "), Ensure a return statement
(200, "\n"), End of code block
]
Apply constrained decoding using the 'constrain' function from phi_3_vision_mlx.
constrain(prompt, constraints)
The `constrain` function can also guide the model to provide reasoning before concluding with an answer. This approach can be especially helpful for multiple-choice questions, such as those in the Massive Multitask Language Understanding (MMLU) benchmark, where the model's thought process is as crucial as its final selection.
python
prompts = [
"A 20-year-old woman presents with menorrhagia for the past several years. She says that her menses “have always been heavy”, and she has experienced easy bruising for as long as she can remember. Family history is significant for her mother, who had similar problems with bruising easily. The patient's vital signs include: heart rate 98/min, respiratory rate 14/min, temperature 36.1°C (96.9°F), and blood pressure 110/87 mm Hg. Physical examination is unremarkable. Laboratory tests show the following: platelet count 200,000/mm3, PT 12 seconds, and PTT 43 seconds. Which of the following is the most likely cause of this patient’s symptoms? A: Factor V Leiden B: Hemophilia A C: Lupus anticoagulant D: Protein C deficiency E: Von Willebrand disease",
"A 25-year-old primigravida presents to her physician for a routine prenatal visit. She is at 34 weeks gestation, as confirmed by an ultrasound examination. She has no complaints, but notes that the new shoes she bought 2 weeks ago do not fit anymore. The course of her pregnancy has been uneventful and she has been compliant with the recommended prenatal care. Her medical history is unremarkable. She has a 15-pound weight gain since the last visit 3 weeks ago. Her vital signs are as follows: blood pressure, 148/90 mm Hg; heart rate, 88/min; respiratory rate, 16/min; and temperature, 36.6℃ (97.9℉). The blood pressure on repeat assessment 4 hours later is 151/90 mm Hg. The fetal heart rate is 151/min. The physical examination is significant for 2+ pitting edema of the lower extremity. Which of the following tests o should confirm the probable condition of this patient? A: Bilirubin assessment B: Coagulation studies C: Hematocrit assessment D: Leukocyte count with differential E: 24-hour urine protein"
]
Apply vanilla constrained decoding
constrain(prompts, constraints=[(30, ' The correct answer is'), (10, 'X.')], blind_model=True, quantize_model=True, use_beam=False)
Apply constrained beam decoding (ACB)
constrain(prompts, constraints=[(30, ' The correct answer is'), (10, 'X.')], blind_model=True, quantize_model=True, use_beam=True)
The constraints encourage a structured response that includes the thought process, making the output more informative and transparent:
< Generated text for prompt 0 >
The most likely cause of this patient's menorrhagia and easy bruising is E: Von Willebrand disease. The correct answer is Von Willebrand disease.
< Generated text for prompt 1 >
The patient's hypertension, edema, and weight gain are concerning for preeclampsia. The correct answer is E: 24-hour urine protein.
Multiple Choice Selection
The `choose` function provides a straightforward way to select the best option from a set of choices for a given prompt. This is particularly useful for multiple-choice questions or decision-making scenarios.
python
from phi_3_vision_mlx import choose
prompt = "What is the capital of France? A: London B: Berlin C: Paris D: Madrid E: Rome"
result = choose(prompt)
print(result) Output: 'C'
Using with custom choices
custom_prompt = "Which color is associated with stopping at traffic lights? R: Red Y: Yellow G: Green"
custom_result = choose(custom_prompt, choices='RYG')
print(custom_result) Output: 'R'
Batch processing
prompts = [
"What is the largest planet in our solar system? A: Earth B: Mars C: Jupiter D: Saturn",
"Which element has the chemical symbol 'O'? A: Osmium B: Oxygen C: Gold D: Silver"
]
batch_results = choose(prompts)
print(batch_results) Output: ['C', 'B']
Model and Cache Quantization
python
Model quantization
generate("Describe the water cycle.", quantize_model=True)
Cache quantization
generate("Explain quantum computing.", quantize_cache=True)
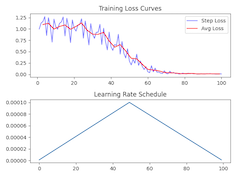
(Q)LoRA Fine-tuning
Training a LoRA Adapter
python
from phi_3_vision_mlx import train_lora
train_lora(
lora_layers=5, Number of layers to apply LoRA
lora_rank=16, Rank of the LoRA adaptation
epochs=10, Number of training epochs
lr=1e-4, Learning rate
warmup=0.5, Fraction of steps for learning rate warmup
dataset_path="JosefAlbers/akemiH_MedQA_Reason"
)
Generating Text with LoRA
python
generate("Describe the potential applications of CRISPR gene editing in medicine.",
blind_model=True,
quantize_model=True,
use_adapter=True)
Comparing LoRA Adapters
python
from phi_3_vision_mlx import test_lora
Test model without LoRA adapter
test_lora(adapter_path=None)
Output score: 0.6 (6/10)
Test model with the trained LoRA adapter (using default path)
test_lora(adapter_path=True)
Output score: 0.8 (8/10)
Test model with a specific LoRA adapter path
test_lora(adapter_path="/path/to/your/lora/adapter")
2. Agent Interactions
Multi-turn Conversation
python
from phi_3_vision_mlx import Agent
Create an instance of the Agent
agent = Agent()
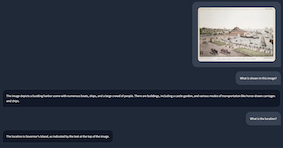
First interaction: Analyze an image
agent('Analyze this image and describe the architectural style:', 'https://images.metmuseum.org/CRDImages/rl/original/DP-19531-075.jpg')
Second interaction: Follow-up question
agent('What historical period does this architecture likely belong to?')
End the conversation: This clears the agent's memory and prepares it for a new conversation
agent.end()
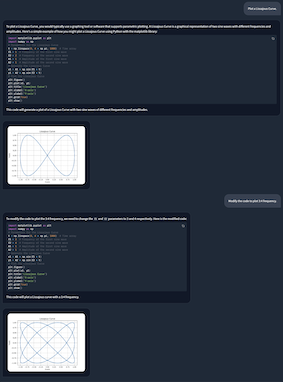
Generative Feedback Loop
python
Ask the agent to generate and execute code to create a plot
agent('Plot a Lissajous Curve.')
Ask the agent to modify the generated code and create a new plot
agent('Modify the code to plot 3:4 frequency')
agent.end()
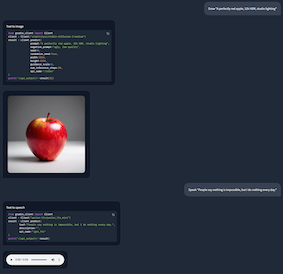
External API Tool Use
python
Request the agent to generate an image
agent('Draw "A perfectly red apple, 32k HDR, studio lighting"')
agent.end()
Request the agent to convert text to speech
agent('Speak "People say nothing is impossible, but I do nothing every day."')
agent.end()
3. Custom Toolchains
Example 1. In-Context Learning Agent
python
from phi_3_vision_mlx import add_text
Define the toolchain as a string
toolchain = """
prompt = add_text(prompt)
responses = generate(prompt, images)
"""
Create an Agent instance with the custom toolchain
agent = Agent(toolchain, early_stop=100)
Run the agent
agent('How to inspect API endpoints? https://raw.githubusercontent.com/gradio-app/gradio/main/guides/08_gradio-clients-and-lite/01_getting-started-with-the-python-client.md')
Example 2. Retrieval Augmented Coding Agent
python
from phi_3_vision_mlx import VDB
import datasets
Simulate user input
user_input = 'Comparison of Sortino Ratio for Bitcoin and Ethereum.'
Create a custom RAG tool
def rag(prompt, repo_id="JosefAlbers/sharegpt_python_mlx", n_topk=1):
ds = datasets.load_dataset(repo_id, split='train')
vdb = VDB(ds)
context = vdb(prompt, n_topk)[0][0]
return f'{context}\n<|end|>\n<|user|>\nPlot: {prompt}'
Define the toolchain
toolchain_plot = """
prompt = rag(prompt)
responses = generate(prompt, images)
files = execute(responses, step)
"""
Create an Agent instance with the RAG toolchain
agent = Agent(toolchain_plot, False)
Run the agent with the user input
_, images = agent(user_input)
Example 3. Multi-Agent Interaction
python
Continued from Example 2 above
agent_writer = Agent(early_stop=100)
agent_writer(f'Write a stock analysis report on: {user_input}', images)
Example 4. External LLM Integration
python
Create Agent with Mistral-7B-Instruct-v0.3 instead
agent = Agent(toolchain = "responses, history = mistral_api(prompt, history)")
Generate a neurology ICU admission note
agent('Write a neurology ICU admission note.')
Follow-up questions (multi-turn conversation)
agent('Give me the inpatient BP goal for this patient.')
agent('DVT ppx for this pt?')
agent("What is the pt's px?")
End
agent.end()
Examples
For more advanced and detailed examples, including multi-modal processing and integration with external libraries, please see the `examples.py` file in the root directory of this project.
Here's a quick preview of what you can find in examples.py:
python
Multimodal Reddit Thread Summarization
from rd2md import rd2md
from pathlib import Path
import json
filename, contents, images = rd2md()
prompt = 'Write an executive summary of above (max 200 words). The article should capture the diverse range of opinions and key points discussed in the thread, presenting a balanced view of the topic without quoting specific users or comments directly. Focus on organizing the information cohesively, highlighting major arguments, counterarguments, and any emerging consensus or unresolved issues within the community.'
prompts = [f'{s}\n\n{prompt}' for s in contents]
results = [generate(prompts[i], images[i], max_tokens=512, blind_model=False, quantize_model=True, quantize_cache=False, verbose=False) for i in range(len(prompts))]
with open(Path(filename).with_suffix('.json'), 'w') as f:
json.dump({'prompts':prompts, 'images':images, 'results':results}, f, indent=4)
<details><summary>Click to expand output</summary><pre>
The discussion on the LLaMA 3.1 model has sparked a variety of reactions and interpretations within the community. The model's potential for 128k context and multimodal capabilities has generated excitement, with some users expressing hope for its release. However, there is skepticism regarding the authenticity of the information, as the link provided is not from an official Hugging Face repository. The possibility of multimodal features being part of LLaMA 4 instead of LLaMA 3.1 has been suggested, leading to further confusion. The community is divided on whether the model's release is imminent or not, with some users questioning the timing and others eagerly anticipating its arrival. The benchmarks shared by users have been scrutinized, with some pointing out inconsistencies and others defending their validity. The thread also touches upon the broader implications of such AI advancements, including the impact on the industry and the potential for future innovations. Despite the differing viewpoints, there is a consensus that the AI field is rapidly evolving, and the community is closely watching for any official announcements from Meta.<|end|>
The discussion on the feasibility of running the 405B model locally has sparked a variety of opinions within the community. While some users express skepticism about the possibility, citing the model's size and the limitations of current hardware, others are optimistic, pointing to advancements in technology that could make it viable. The debate centers around the technical requirements for running such a model, including the necessary hardware specifications and the potential for optimization through techniques like quantization. There is a consensus that significant technical challenges exist, but the community is divided on whether these can be overcome in the near future. The conversation also touches on the broader implications of model size and performance, with some users questioning the practicality of running large models on local machines. Despite the differing viewpoints, there is a shared understanding that the discussion is ongoing and that advancements in technology may eventually change the current limitations. The community is actively seeking solutions and is hopeful that future developments will make running large models like 405B more accessible.<|end|>
The discussion on Instruction tuned models, specifically comparing Llama 3.1 8B and 70B, has sparked a variety of opinions within the community. Some users have noted that the 70B model outperforms the 8B model in certain benchmarks, such as HumanEval, despite the 8B model having a higher score in general benchmarks. This has led to a debate on the relevance of these benchmarks, with some users suggesting that they may be less indicative of model performance due to their simplicity. The consensus on the effect of distillation on model performance is mixed, with some users observing that distilled models like 70B may perform differently compared to their predecessors. The community is divided on whether these differences are significant enough to warrant a shift in model choice for production use cases. The discussion also touches on the impact of longer context on model performance, with some users suggesting that it may lead to performance degradation. Overall, the community is grappling with the implications of these findings and how they should influence the choice of models for different applications.<|end|>
</pre></details>
This example demonstrates how to use Phi-3-MLX to generate summaries of Reddit posts and their comments, including both textual content and associated images. It showcases the model's ability to process and synthesize information from multi-modal online discussions.
Benchmarks
python
from phi_3_vision_mlx import benchmark
benchmark()
| Task | Vanilla Model | Quantized Model | Quantized Cache | LoRA Adapter |
|-----------------------|---------------|-----------------|-----------------|--------------|
| Text Generation | 8.67 tps | 54.37 tps | 7.75 tps | 8.67 tps |
| Image Captioning | 7.84 tps | 33.37 tps | 2.87 tps | 7.61 tps |
| Batched Generation | 104.86 tps | 184.39 tps | 75.76 tps | 94.49 tps |
*(On M1 Max 64GB)*
Documentation
API references and additional information are available at:
https://josefalbers.github.io/Phi-3-Vision-MLX/
License
This project is licensed under the [MIT License](LICENSE).
Citation
<a href="https://zenodo.org/doi/10.5281/zenodo.11403221"><img src="https://zenodo.org/badge/806709541.svg" alt="DOI"></a>