Generic Spark support as a Provider
Featureform has had support for Spark on EMR and Spark on Databricks for a while. We’ve generalized our Spark implementation to handle all versions of Spark using any of S3, GCS, Azure Blob Store, or HDFS as a backing store!
Here are some examples:
Spark with GCS backend
python
spark_creds = ff.SparkCredentials(
master=master_ip_or_local,
deploy_mode="client",
python_version=cluster_py_version,
)
gcp_creds = ff.GCPCredentials(
project_id=project_id,
credentials_path=path_to_gcp_creds,
)
gcs = ff.register_gcs(
name=gcs_provider_name,
credentials=gcp_creds,
bucket_name=”bucket_name”,
bucket_path="directory/",
)
spark = ff.register_spark(
name=spark_provider_name,
description="A Spark deployment we created for the Featureform quickstart",
team="featureform-team",
executor=spark_creds,
filestore=gcs,
)
Databricks with Azure
python
databricks = ff.DatabricksCredentials(
host=host,
token=token,
cluster_id=cluster,
)
azure_blob = ff.register_blob_store(
name=”blob”,
account_name=os.getenv("AZURE_ACCOUNT_NAME", None),
account_key=os.getenv("AZURE_ACCOUNT_KEY", None),
container_name=os.getenv("AZURE_CONTAINER_NAME", None),
root_path="testing/ff",
)
spark = ff.register_spark(
name=”spark-databricks-azure”,
description="A Spark deployment we created for the Featureform quickstart",
team="featureform-team",
executor=databricks,
filestore=azure_blob,
)
EMR with S3
python
spark_creds = ff.SparkCredentials(
master=master_ip_or_local,
deploy_mode="client",
python_version=cluster_py_version,
)
aws_creds = ff.AWSCredentials(
aws_access_key_id=os.getenv("AWS_ACCESS_KEY_ID", None),
aws_secret_access_key=os.getenv("AWS_SECRET_KEY", None),
)
s3 = ff.register_s3(
name="s3-quickstart",
credentials=aws_creds,
bucket_path=os.getenv("S3_BUCKET_PATH", None),
bucket_region=os.getenv("S3_BUCKET_REGION", None),
)
spark = ff.register_spark(
name="spark-generic-s3",
description="A Spark deployment we created for the Featureform quickstart",
team="featureform-team",
executor=spark_creds,
filestore=s3,
)
Spark with HDFS
python
spark_creds = ff.SparkCredentials(
master=os.getenv("SPARK_MASTER", "local"),
deploy_mode="client",
python_version="3.7.16",
)
hdfs = ff.register_hdfs(
name="hdfs_provider",
host=host,
port="9000",
username="hduser"
)
spark = ff.register_spark(
name="spark-hdfs",
description="A Spark deployment we created for the Featureform quickstart",
team="featureform-team",
executor=spark_creds,
filestore=hdfs,
)
You can read more in the docs.
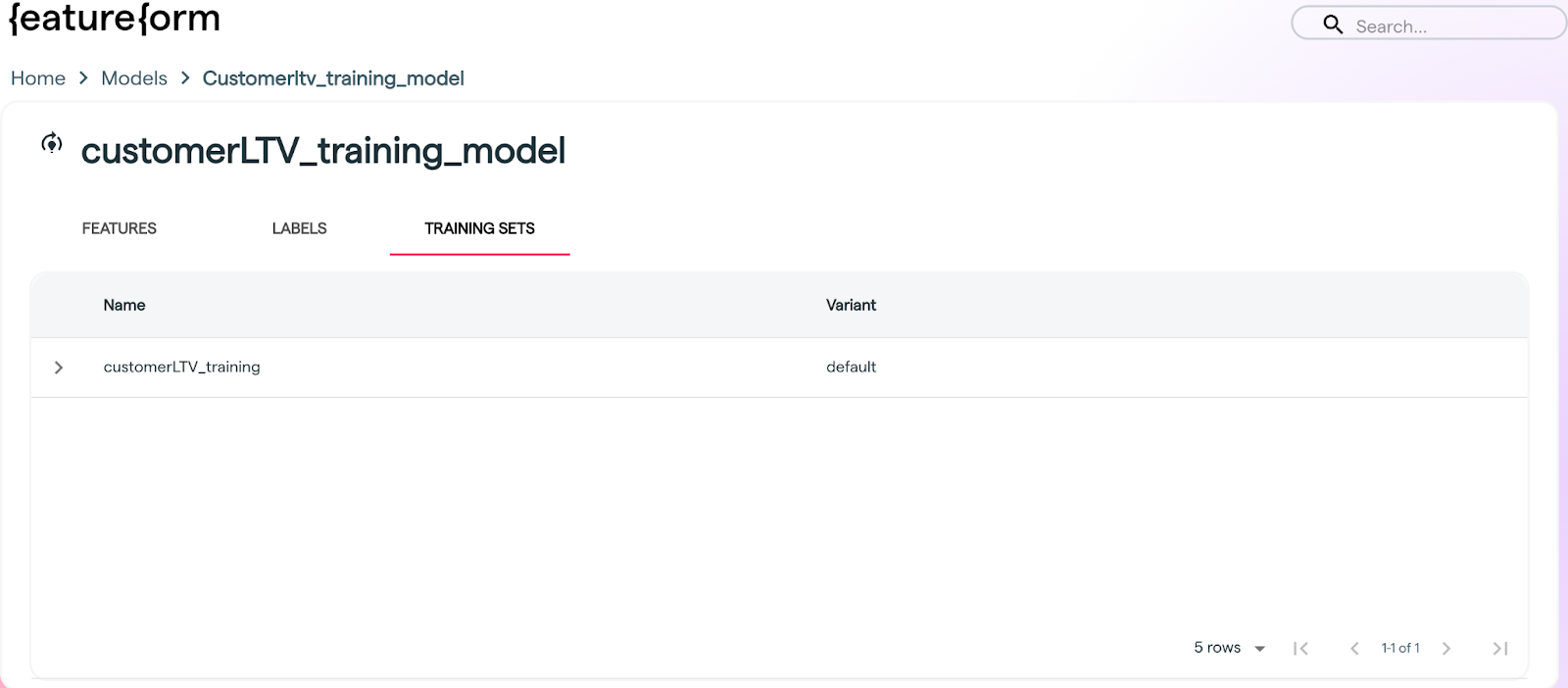
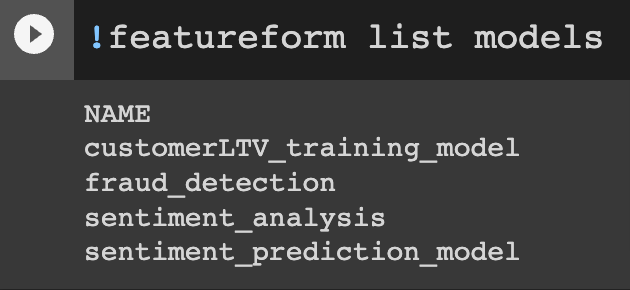
Track which models are using features / training sets at serving time
A highly requested feature was to add a lineage link between models and their feature & training set. Now when you serve a feature and training set you can include an *optional* model argument.
python
client.features("review_text", entities={"order": "df8e5e994bcc820fcf403f9a875201e6"}, model="sentiment_analysis")
`
python
client.training_set(“CustomerLTV_Training”, “default”, model=”linear_ltv_model”)
It can then be viewed via the CLI & the Dashboard:
**Dashboard**
**CLI**
You can learn more in the [docs](https://docs.featureform.com/getting-started/serving-for-inference-and-training#model-registration)
Backup & Recovery now available in open-source Featureform
Backup and recovery was originally exclusive to our enterprise offering. It is our goal to open-source everything in the product that isn’t related to governance, though we often first pilot new features with clients as we nail down the API.
Enable Backups
1. Create a k8s secret with information on where to store backups.
shell
> python backup/create_secret.py --help
Usage: create_secret.py [OPTIONS] COMMAND [ARGS]...
Generates a Kubernetes secret to store Featureform backup data.
Use this script to generate the Kubernetes secret, then apply it with:
`kubectl apply -f backup_secret.yaml`
Options:
-h, --help Show this message and exit.
Commands:
azure Create secret for azure storage containers
gcs Create secret for GCS buckets
s3 Create secret for S3 buckets
2. Upgrade your Helm cluster (if it was created without backups enabled)
shell
helm upgrade featureform featureform/featureform [FLAGS] --set backup.enable=true --set backup.schedule=<schedule>
Where schedule is in cron syntax, for example an hourly backup would look like:
`"0 * * * *"`
Recover from backup
Recovering from a backup is simple. In backup/restore, edit the .env-template file with your cloud provider name and credentials, then rename to .env. A specific snapshot can be used by filling in the SNAPSHOT_NAME variable in the .env file.
After that, run `recover.sh` in that directory.
You can learn more in the [docs](https://docs.featureform.com/deployment/backup-and-restore).
Ability to rotate key and change provider credentials
Prior to this release, if you were to rotate a key and/or change a credential you’d have to create a new provider. We made things immutable to avoid people accidentally overwriting each other's providers; however, this blocked the ability to rotate keys. Now, provider changes work as an upsert.
For example if you had registered Databricks and applied it like this:
python
databricks = ff.DatabricksCredentials(
host=host,
token=old_token,
cluster_id=cluster,
)
You could change it by simply changing the config and re-applying it.
python
databricks = ff.DatabricksCredentials(
host=host,
token=new_token,
cluster_id=cluster,
)
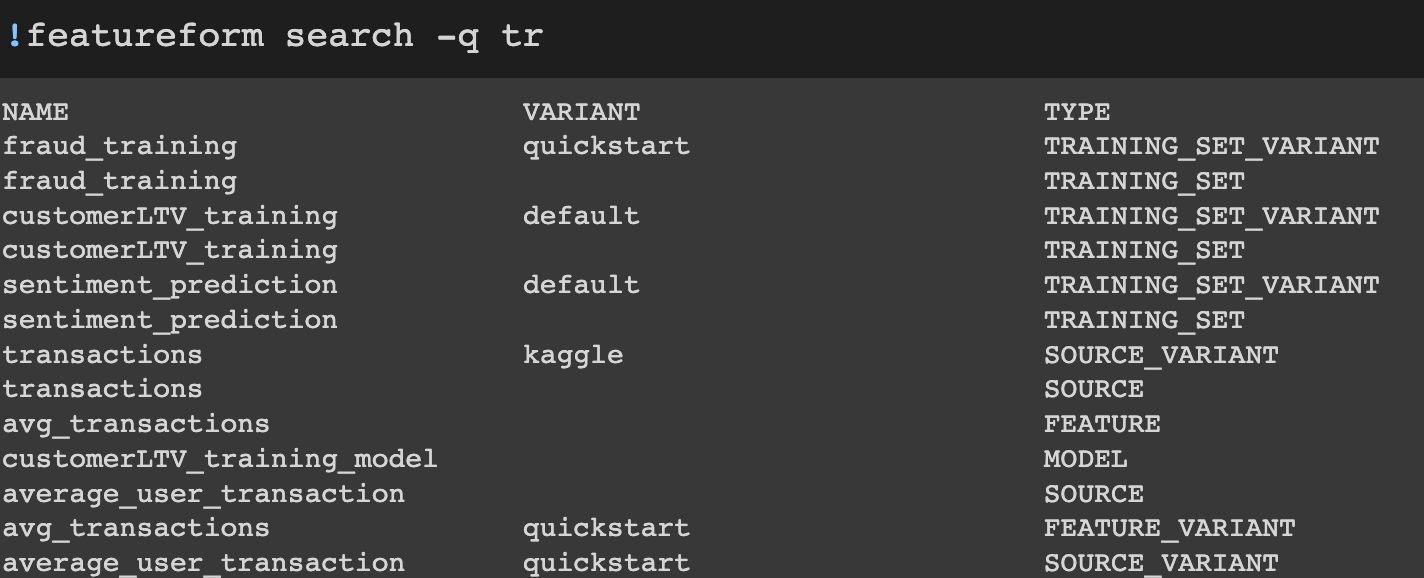
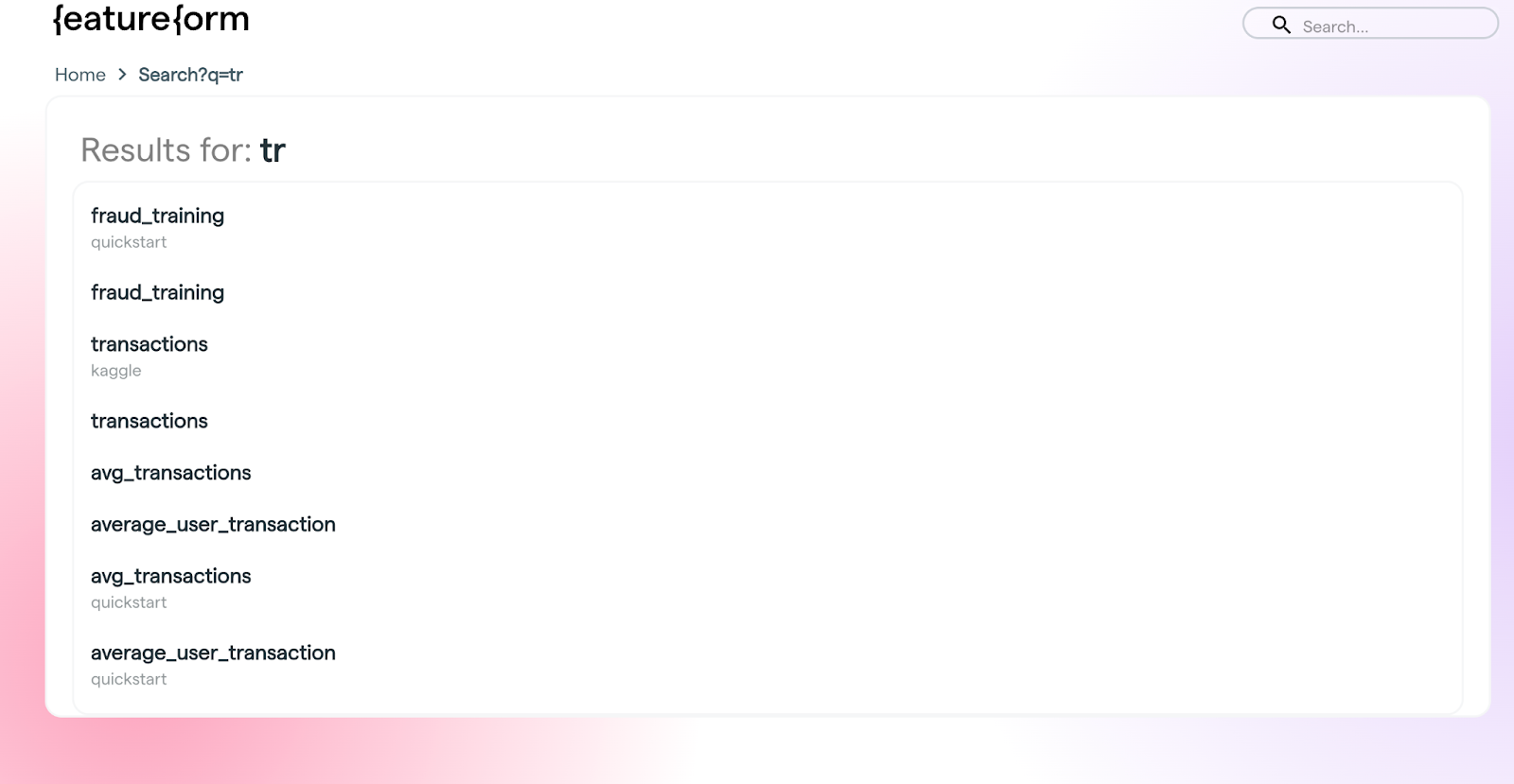
Ability to do full-text search on resources from the CLI
Prior to this release, you could only search resources from the dashboard. We’ve added the same functionality into the CLI. Our goal is to stay as close to feature parity between the dashboard and CLI as possible.
**CLI**
**Dashboard**
Enhancements
Mutable Providers
Featureform has historically made all resources immutable to solve a variety of different problems. This includes upstreams changing and breaking downstreams. Over the next couple releases we expect to dramatically pull back on forcing immutability while still avoiding the most common types of problems.
Featureform apply now works as an Upsert. For providers specifically, you can change most of their fields. This also makes it possible to rotate secrets and change credentials as outlined earlier in these release notes.
Support for Legacy Snowflake Credentials
Older deployments of Snowflake used an Account Locator rather than an Organization/Account pair to connect, you can now use our [register_snowflake_legacy](https://docs.featureform.com/training-offline-stores/snowflake#legacy-credentials) method.
python
ff.register_snowflake_legacy(
name = "snowflake_docs",
description = "Example training store",
team = "Featureform",
username = snowflake_username,
password: snowflake_password,
account_locator: snowflake_account_locator,
database: snowflake_database,
schema: snowflake_schema,
)
You can learn more in the [docs](https://docs.featureform.com/training-offline-stores/snowflake#legacy-credentials).
Experimental
Custom Transformation-specific Container Limits for Pandas on K8s transformations
Pandas on K8s is still an experimental feature that we’re continuing to expand on. You were previously able to specify container limits for all, but now for specifically heavy or light transformations you can get more granular about your specifications as follows:
resource_specs = K8sResourceSpecs(
cpu_request="250m",
cpu_limit="50Mi",
memory_request="500m",
memory_limit="100Mi"
)
k8s.df_transformation(
inputs=[("transactions", “v2”)],
resource_specs=resource_specs
)
def transform(transactions):
pass
You can learn more in the [docs](https://docs.featureform.com/training-offline-stores/kubernetes#using-a-custom-image-per-transformation).