New models
Distil-Whisper
Distil-Whisper is a distilled version of Whisper that is 6 times faster, 49% smaller, and performs within 1% word error rate (WER) on out-of-distribution data. It was proposed in the paper [Robust Knowledge Distillation via Large-Scale Pseudo Labelling](https://arxiv.org/abs/2311.00430).
Distil-Whisper copies the entire encoder from Whisper, meaning it retains Whisper's robustness to different audio conditions. It only copies 2 decoder layers, which significantly reduces the time taken to auto-regressively generate text tokens:
<img src="https://huggingface.co/datasets/distil-whisper/figures/resolve/main/architecture.png" width="800">
Distil-Whisper is MIT licensed and directly available in the Transformers library with chunked long-form inference, Flash Attention 2 support, and Speculative Decoding. For details on using the model, refer to the [following instructions](https://github.com/huggingface/distil-whisper#1-usage).
Joint work from sanchit-gandhi, patrickvonplaten and srush.
* [Assistant Generation] Improve Encoder Decoder by patrickvonplaten in 26701
* [WhisperForCausalLM] Add WhisperForCausalLM for speculative decoding by patrickvonplaten in 27195
* [Whisper, Bart, MBart] Add Flash Attention 2 by patrickvonplaten in 27203
Fuyu
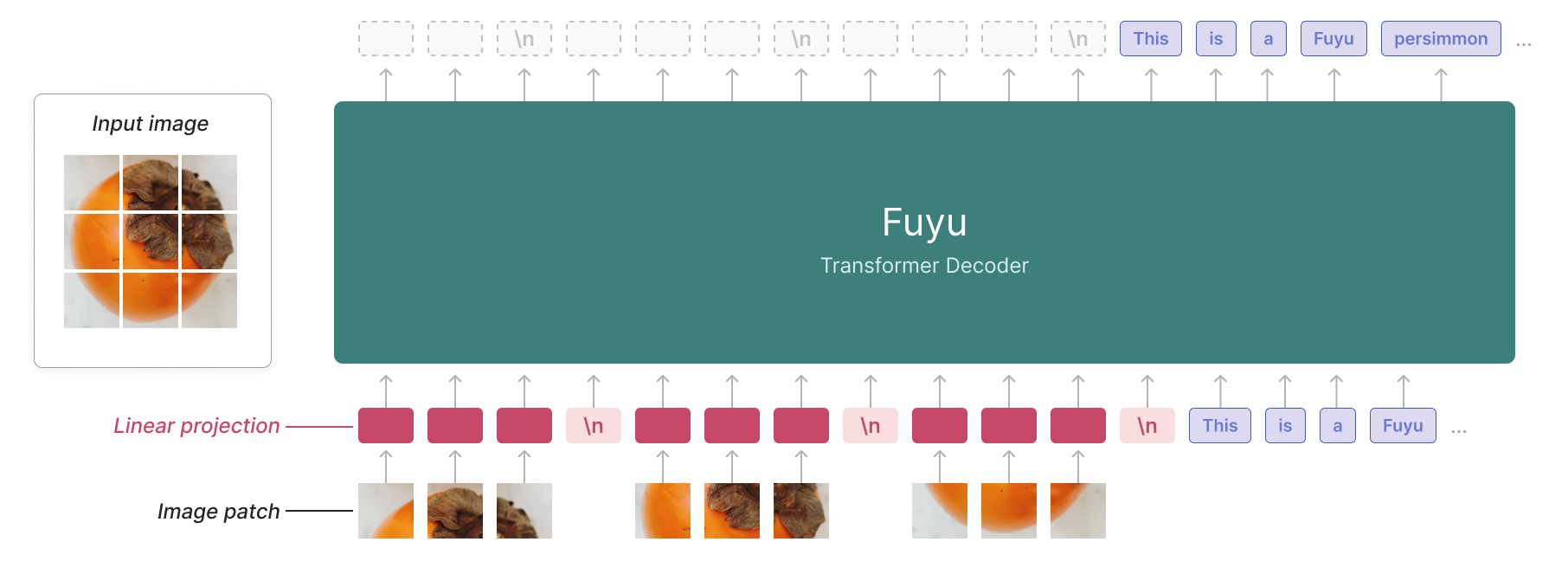
The Fuyu model was created by [ADEPT](https://www.adept.ai/blog/fuyu-8b), and authored by Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, Sağnak Taşırlar.
The authors introduced Fuyu-8B, a decoder-only multimodal model based on the classic transformers architecture, with query and key normalization. A linear encoder is added to create multimodal embeddings from image inputs.
By treating image tokens like text tokens and using a special image-newline character, the model knows when an image line ends. Image positional embeddings are removed. This avoids the need for different training phases for various image resolutions. With 8 billion parameters and licensed under CC-BY-NC, Fuyu-8B is notable for its ability to handle both text and images, its impressive context size of 16K, and its overall performance.
Joint work from molbap, pcuenca, amyeroberts, ArthurZucker
* Add fuyu model by molbap in 26911
* Fuyu: improve image processing by molbap in 27007
SeamlessM4T

The SeamlessM4T model was proposed in [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) by the Seamless Communication team from Meta AI.
SeamlessM4T is a collection of models designed to provide high quality translation, allowing people from different linguistic communities to communicate effortlessly through speech and text.
SeamlessM4T enables multiple tasks without relying on separate models:
- Speech-to-speech translation (S2ST)
- Speech-to-text translation (S2TT)
- Text-to-speech translation (T2ST)
- Text-to-text translation (T2TT)
- Automatic speech recognition (ASR)
[SeamlessM4TModel](https://huggingface.co/docs/transformers/main/en/model_doc/seamless_m4t#transformers.SeamlessM4TModel) can perform all the above tasks, but each task also has its own dedicated sub-model.
* Add Seamless M4T model by ylacombe in 25693
Kosmos-2
The KOSMOS-2 model was proposed in [Kosmos-2: Grounding Multimodal Large Language Models to the World](https://arxiv.org/abs/2306.14824) by Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, Furu Wei.
<div style="text-align: center">
<img src="https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/annotated_snowman.jpg" width="500" height="400" >
</div>
KOSMOS-2 is a Transformer-based causal language model and is trained using the next-word prediction task on a web-scale dataset of grounded image-text pairs [GRIT](https://huggingface.co/datasets/zzliang/GRIT). The spatial coordinates of the bounding boxes in the dataset are converted to a sequence of location tokens, which are appended to their respective entity text spans (for example, a snowman followed by <patch_index_0044><patch_index_0863>). The data format is similar to “hyperlinks” that connect the object regions in an image to their text span in the corresponding caption.
* Add `Kosmos-2` model by ydshieh in 24709
Owl-v2
OWLv2 was proposed in [Scaling Open-Vocabulary Object Detection](https://arxiv.org/abs/2306.09683) by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up [OWL-ViT](https://huggingface.co/docs/transformers/main/en/model_doc/owlvit) using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
* Add OWLv2, bis by NielsRogge in 26668
🚨🚨🚨 Safetensors by default for `torch` serialization 🚨🚨🚨
Version v4.35.0 now puts `safetensors` serialization by default. This is a significant change targeted at making users of the Hugging Face Hub, `transformers`, and any downstream library leveraging it safer.
The [`safetensors`](https://github.com/huggingface/safetensors) library is a safe serialization framework for machine learning tensors. It has been audited and will become the default serialization framework for several organizations (Hugging Face, EleutherAI, Stability AI).
It was already the **default loading mechanism** since v4.30.0 and would therefore already default to loading `model.safetensors` files instead of `pytorch_model.bin` if these were present in the repository.
With v4.35.0, any call to `save_pretrained` for torch models will now save a `safetensors` file. This `safetensors` file is in the PyTorch format, but can be loaded in TensorFlow and Flax models alike.
⚠️ If you run into any issues with this, please let us know ASAP in the issues so that we may help you. Namely, the following errors may indicate something is up:
- Loading a `safetensors` file and having a warning mentioning missing weights unexpectedly
- Obtaining completely wrong/random results at inference after loading a pretrained model that you have saved in `safetensors`
If you wish to continue saving files in the `.bin` format, you can do so by specifying `safe_serialization=False` in all your `save_pretrained` calls.
* Safetensors serialization by default by LysandreJik in 27064
Chat templates
Chat templates have been expanded with the addition of the `add_generation_prompt` argument to `apply_chat_template()`. This has also enabled us to rework the [ConversationalPipeline](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#transformers.ConversationalPipeline) class to use chat templates. Any model with a chat template is now automatically usable through `ConversationalPipeline`.
* Add add_generation_prompt argument to apply_chat_template by Rocketknight1 in 26573
* Conversation pipeline fixes by Rocketknight1 in 26795
Guides
Two new guides on LLMs were added the library:
* [docs] LLM prompting guide by MKhalusova in 26274
* [docs] Optimizing LLMs by patrickvonplaten in 26058
Quantization
Exllama-v2 integration
Exllama-v2 provides better GPTQ kernel for higher throughput and lower latency for GPTQ models. The original [code](https://github.com/turboderp/exllamav2) can be found here.
* add exllamav2 arg by SunMarc in 26437
* Add exllamav2 better by SunMarc in 27111
You will need the latest versions of `optimum` and `auto-gptq`. Read more about the integration [here](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#exllama-kernels-for-faster-inference).
AWQ integration
AWQ is a new and popular quantization scheme, already used in various libraries such as TGI, vllm, etc. and known to be faster than GPTQ models according to some benchmarks. The original code can be found [here](https://github.com/mit-han-lab/llm-awq/) and [here](https://arxiv.org/abs/2306.00978) you can read more about the original paper.

We support AWQ inference with original kernels as well as kernels provided through [`autoawq`](https://github.com/casper-hansen/AutoAWQ/) package that you can simply install with `pip install autoawq`.
* [`core` / `Quantization` ] AWQ integration by younesbelkada in 27045
We also provide an example script on [how to push quantized weights on the hub on the original repository](https://github.com/mit-han-lab/llm-awq/blob/main/examples/convert_to_hf.py).
Read more about the benchmarks and the integration [here](https://huggingface.co/docs/transformers/main/en/main_classes/quantization#awq-integration)
GPTQ on CPU !
You can now run GPTQ models on CPU using the latest version of `auto-gptq` thanks to vivekkhandelwal1 !
* Add support for loading GPTQ models on CPU by vivekkhandelwal1 in 26719
Attention mask refactor
We refactored the attention mask logic for major models in transformers. For instance, we removed `padding_mask` argument which was ambiguous for some users
* Remove ambiguous `padding_mask` and instead use a 2D->4D Attn Mask Mapper by patrickvonplaten in 26792
* [Attention Mask] Refactor all encoder-decoder attention mask by patrickvonplaten in 27086
Flash Attention 2 for more models + quantization fine-tuning bug fix
`Gpt-bigcode` (starcoder), whisper, Bart and MBart now supports FA-2 ! Use it by simply passing `use_flash_attention_2=True` to `from_pretrained`. Some bugfixes with respect to mixed precision training with FA2 have been also addressed.
* Add flash attention for `gpt_bigcode` by susnato in 26479
* [`FA2`] Fix flash attention 2 fine-tuning with Falcon by younesbelkada in 26852
* [Whisper, Bart, MBart] Add Flash Attention 2 by patrickvonplaten in 27203
A bugfix with respect to fine-tuning with FA-2 in bfloat16 was addressed. You should now smoothly fine-tune FA-2 models in bfloat16 using quantized base models.
* 🚨🚨🚨 [`Quantization`] Store the original dtype in the config as a private attribute 🚨🚨🚨 by younesbelkada in 26761
* [`FA-2`] Final fix for FA2 dtype by younesbelkada in 26846
Neftune
NEFTune is a new technique to boost Supervised Fine-tuning performance by adding random noise on the embedding vector. Read more about it on the original paper [here](https://arxiv.org/abs/2310.05914)

We propose a very simple API for users to benefit from this technique, simply pass a valid `neftune_noise_alpha` parameter to `TrainingArguments`
Read more about the API [here](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#boost-your-fine-tuning-performances-using-neftune)
* [FEAT] Add Neftune into transformers Trainer by younesbelkada in 27141
Gradient checkpointing refactor
We have refactored the gradient checkpointing API so that users can pass keyword arguments supported by `torch.utils.checkpoint.checkpoint` directly through `gradient_checkpointing_kwargs` when calling `gradient_checkpointing_enable()`, e.g.
python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
model.gradient_checkpointing_enable(gradient_checkpointing_kwargs={"use_reentrant": False})
`gradient_checkpointing_kwargs` is also supported with `Trainer` through `TrainingArguments`.
* [`Trainer` / `GC`] Add `gradient_checkpointing_kwargs` in trainer and training arguments by younesbelkada in 27068
* [`core`] Refactor of `gradient_checkpointing` by younesbelkada in 27020
* [`core`/ `GC` / `tests`] Stronger GC tests by younesbelkada in 27124
* Fix import of torch.utils.checkpoint by NielsRogge in 27155
The refactor should be totally backward compatible with previous behaviour. For superusers, you can still use the attribute `gradient_checkpointing` on model's submodules to control the activation / deactivation of gradient_checkpointing.
Breaking changes
* 🚨🚨🚨 [`Quantization`] Store the original dtype in the config as a private attribute 🚨🚨🚨 by younesbelkada in 26761
* 🚨🚨 Generate: change order of ops in beam sample to avoid nans by gante in 26843
* 🚨🚨 Raise error when no speaker embeddings in speecht5._generate_speech by ylacombe in 26418
Bugfixes and improvements
* [`Nougat`] from transformers import * by ArthurZucker in 26562
* [Whisper] Allow basic text normalization by sanchit-gandhi in 26149
* 🌐 [i18n-KO] Translated `semantic_segmentation.md` to Korean by jungnerd in 26515
* [Tokenizers] Skip tests temporarily by LysandreJik in 26574
* docs: feat: add clip notebook resources from OSSCA community by junejae in 26505
* Extend Trainer to enable Ascend NPU to use the fused Adamw optimizer when training by statelesshz in 26194
* feat: add trainer label to wandb run upon initialization by parambharat in 26466
* Docstring check by sgugger in 26052
* refactor: change default block_size by pphuc25 in 26229
* [Mistral] Update config docstring by sanchit-gandhi in 26593
* Add Copied from statements to audio feature extractors that use the floats_list function by dg845 in 26581
* Fix embarrassing typo in the doc chat template! by Rocketknight1 in 26596
* Fix encoder->decoder typo bug in convert_t5x_checkpoint_to_pytorch.py by soyoung97 in 26587
* skip flaky hub tests by ArthurZucker in 26594
* Update mistral.md to update 404 link by Galland in 26590
* [Wav2Vec2] Fix tokenizer set lang by sanchit-gandhi in 26349
* add zh translation for installation by yyLeaves in 26084
* [ `NougatProcessor`] Fix the default channel by ArthurZucker in 26608
* [`GPTNeoX`] Faster rotary embedding for GPTNeoX (based on llama changes) by ArthurZucker in 25830
* [Falcon] Set `use_cache=False` before creating `presents` which relies on `use_cache` by yundai424 in 26328
* Fix failing tests on `main` due to torch 2.1 by ydshieh in 26607
* Make `ModelOutput` serializable by cbensimon in 26493
* [`core`] fix silent bug `keep_in_fp32` modules by younesbelkada in 26589
* 26566 swin2 sr allow in out channels by marvingabler in 26568
* Don't close ClearML task if it was created externally by eugen-ajechiloae-clearml in 26614
* Fix `transformers-pytorch-gpu` docker build by ydshieh in 26615
* [docs] Update to scripts building index.md by MKhalusova in 26546
* Don't install `pytorch-quantization` in Doc Builder docker file by ydshieh in 26622
* Remove unnecessary `view`s of `position_ids` by ramiro050 in 26059
* Fixed inconsistency in several fast tokenizers by Towdo in 26561
* Update tokenization_code_llama_fast.py by andyl98 in 26576
* Remove unnecessary unsqueeze - squeeze in rotary positional embedding by fxmarty in 26162
* Update chat template docs with more tips on writing a template by Rocketknight1 in 26625
* fix RoPE t range issue for fp16 by rui-ren in 26602
* Fix failing `MusicgenTest .test_pipeline_text_to_audio` by ydshieh in 26586
* remove SharedDDP as it is deprecated by statelesshz in 25702
* [`LlamaTokenizerFast`] Adds edge cases for the template processor by ArthurZucker in 26606
* [docstring] Fix docstring for `AlbertConfig` by ydshieh in 26636
* docs(zh): review and punctuation & space fix by wfjsw in 26627
* [DINOv2] Convert more checkpoints by NielsRogge in 26177
* Fixed malapropism error by Zhreyu in 26660
* fix links in README.md for the GPT, GPT-2, and Llama2 Models by dcarpintero in 26640
* Avoid CI OOM by ydshieh in 26639
* fix typos in idefics.md by dribnet in 26648
* [docstring] Fix docstring CLIP configs by isaac-chung in 26677
* [docstring] Fix docstring for `CLIPImageProcessor` by isaac-chung in 26676
* [docstring] Fix docstring for DonutImageProcessor by abzdel in 26641
* Fix stale bot by LysandreJik in 26692
* [docstring] Fix docstrings for `CLIP` by isaac-chung in 26691
* Control first downsample stride in ResNet by jiqing-feng in 26374
* Fix Typo: table in deepspeed.md by Pairshoe in 26705
* [docstring] Fix docstring for `LlamaConfig` by pavaris-pm in 26685
* fix a typo in flax T5 attention - attention_mask variable is misnamed by giganttheo in 26663
* Fix source_prefix default value by jheitmann in 26654
* [JAX] Replace uses of `jnp.array` in types with `jnp.ndarray`. by hvaara in 26703
* Make Whisper Encoder's sinusoidal PE non-trainable by default by gau-nernst in 26032
* In assisted decoding, pass model_kwargs to model's forward call (fix prepare_input_for_generation in all models) by sinking-point in 25242
* Update docs to explain disabling callbacks using report_to by nebrelbug in 26155
* `Copied from` for test files by ydshieh in 26713
* [docstring] `SwinModel` docstring fix by shivanandmn in 26679
* fix the model card issue as `use_cuda_amp` is no more available by pacman100 in 26731
* Fix stale bot for locked issues by LysandreJik in 26711
* Fix checkpoint path in `no_trainer` scripts by muellerzr in 26733
* Update docker files to use `torch==2.1.0` by ydshieh in 26735
* Revert 20715 by ydshieh in 26734
* [docstring] Fix docstring for `LlamaTokenizer` and `LlamaTokenizerFast` by minhoryang in 26669
* [docstring] Fix docstring for `CodeLlamaTokenizer` by Bojun-Feng in 26709
* add japanese documentation by rajveer43 in 26138
* Translated the accelerate.md file of the documentation to Chinese by liteli1987gmail in 26161
* Fix doctest for `Blip2ForConditionalGeneration` by ydshieh in 26737
* Add many missing spaces in adjacent strings by tomaarsen in 26751
* Warnings controlled by logger level by LysandreJik in 26527
* Fix `PersimmonIntegrationTest` OOM by ydshieh in 26750
* Fix `MistralIntegrationTest` OOM by ydshieh in 26754
* Fix backward compatibility of Conversation by wdhorton in 26741
* [docstring] Fix `UniSpeech`, `UniSpeechSat`, `Wav2Vec2ForCTC` by gizemt in 26664
* [docstring] Update `GPT2` and `Whisper` by McDonnellJoseph in 26642
* [docstring] Fix docstring for 'BertGenerationConfig' by AdwaitSalankar in 26661
* Fix `PerceiverModelIntegrationTest::test_inference_masked_lm` by ydshieh in 26760
* chore: fix typos by afuetterer in 26756
* [`core`] Fix fa-2 import by younesbelkada in 26785
* Skip `TrainerIntegrationFSDP::test_basic_run_with_cpu_offload` if `torch < 2.1` by ydshieh in 26764
* 🌐 [i18n-KO] Translated `big_models.md` to Korean by wonhyeongseo in 26245
* Update expect outputs of `IdeficsProcessorTest.test_tokenizer_padding` by ydshieh in 26779
* [docstring] Fix docstring for `RwkvConfig` by Bojun-Feng in 26782
* Fix num. of minimal calls to the Hub with peft for pipeline by ydshieh in 26385
* [docstring] fix docstring `DPRConfig` by AVAniketh0905 in 26674
* Disable default system prompt for LLaMA by Rocketknight1 in 26765
* Fix Falcon generation test by Rocketknight1 in 26770
* Fixed KeyError for Mistral by MatteoRaso in 26682
* [`Flava`] Fix flava doc by younesbelkada in 26789
* Add CLIP resources by eenzeenee in 26534
* translation brazilian portuguese by alvarorichard in 26769
* Fixed typos by Zhreyu in 26810
* [docstring] Fix docstring for `CanineConfig` by Sparty in 26771
* Add Japanese translation by shinshin86 in 26799
* [docstring] Fix docstring for `CodeLlamaTokenizerFast` by Bojun-Feng in 26666
* Image-to-Image Task Guide by merveenoyan in 26595
* Make fsdp ram efficient loading optional by pacman100 in 26631
* fix resume_from_checkpoint bug by Jintao-Huang in 26739
* [OWL-ViT, OWLv2] Add resources by NielsRogge in 26822
* Llama tokenizer: remove space in template comment by pcuenca in 26788
* Better way to run AMD CI with different flavors by ydshieh in 26634
* [docstring] Fix bert generation tokenizer by przemL in 26820
* Conversation pipeline fixes by Rocketknight1 in 26795
* Fix Mistral OOM again by ydshieh in 26847
* Chore: Typo fixed in multiple files of docs/source/en/model_doc by SusheelThapa in 26833
* fix: when window_size is passes as array by dotneet in 26800
* Update logits_process.py docstrings to clarify penalty and reward cases (attempt 2) by larekrow in 26784
* [docstring] Fix docstring for LukeConfig by louietouie in 26858
* Fixed a typo in mistral.md by DTennant in 26879*
* Translating `en/internal` folder docs to Japanese 🇯🇵 by rajveer43 in 26747
* Fix TensorFlow pakage check by jayfurmanek in 26842
* Generate: improve docstrings for custom stopping criteria by gante in 26863
* Knowledge distillation for vision guide by merveenoyan in 25619
* Fix Seq2seqTrainer decoder attention mask by Rocketknight1 in 26841
* [`Tokenizer`] Fix slow and fast serialization by ArthurZucker in 26570
* Emergency PR to skip conversational tests to fix CI by Rocketknight1 in 26906
* Add default template warning by Rocketknight1 in 26637
* Refactor code part in documentation translated to japanese by rajveer43 in 26900
* [i18n-ZH] Translated fast_tokenizers.md to Chinese by yyLeaves in 26910
* [`FA-2`] Revert suggestion that broke FA2 fine-tuning with quantized models by younesbelkada in 26916
* [docstring] Fix docstring for `ChineseCLIP` by Sparty in 26880
* [Docs] Make sure important decode and generate method are nicely displayed in Whisper docs by patrickvonplaten in 26927
* Fix and re-enable ConversationalPipeline tests by Rocketknight1 in 26907
* [docstring] Fix docstrings for `CodeGen` by daniilgaltsev in 26821
* Fix license by MedAymenF in 26931
* Pin Keras for now by Rocketknight1 in 26904
* [`FA-2` / `Mistral`] Supprot fa-2 + right padding + forward by younesbelkada in 26912
* Generate: update basic llm tutorial by gante in 26937
* Corrected modalities description in README_ru.md by letohx in 26913
* [docstring] Fix docstring for speech-to-text config by R055A in 26883
* fix set_transform link docs by diegulio in 26856
* Fix Fuyu image scaling bug by pcuenca in 26918
* Update README_hd.md by biswabaibhab007 in 26872
* Added Telugu [te] translations by hakunamatata1997 in 26828
* fix logit-to-multi-hot conversion in example by ranchlai in 26936
* Limit to inferior fsspec version by LysandreJik in 27010
* python falcon doc-string example typo by SoyGema in 26995
* skip two tests by ArthurZucker in 27013
* Nits in Llama2 docstring by osanseviero in 26996
* Change default `max_shard_size` to smaller value by younesbelkada in 26942
* [`NLLB-MoE`] Fix NLLB MoE 4bit inference by younesbelkada in 27012
* [`SeamlessM4T`] fix copies with NLLB MoE int8 by ArthurZucker in 27018
* small typos found by rafaelpadilla in 26988
* Remove token_type_ids from default TF GPT-2 signature by Rocketknight1 in 26962
* Translate `pipeline_tutorial.md` to chinese by jiaqiw09 in 26954
* 🌐 [i18n-ZH] Translate multilingual into Chinese by yyLeaves in 26935
* translate `preprocessing.md` to Chinese by jiaqiw09 in 26955
* Bugfix device map detr model by pedrogengo in 26849
* Fix little typo by mertyyanik in 27028
* 🌐 [i18n-ZH] Translate create_a_model.md into Chinese by yyLeaves in 27026
* Fix key dtype in GPTJ and CodeGen by fxmarty in 26836
* Register ModelOutput as supported torch pytree nodes by XuehaiPan in 26618
* Add `default_to_square_for_size` to `CLIPImageProcessor` by ydshieh in 26965
* Add descriptive docstring to WhisperTimeStampLogitsProcessor by jprivera44 in 25642
* Normalize only if needed by mjamroz in 26049
* [`TFxxxxForSequenceClassifciation`] Fix the eager mode after 25085 by ArthurZucker in 25751
* Safe import of rgb_to_id from FE modules by amyeroberts in 27037
* add info on TRL docs by lvwerra in 27024
* Add fuyu device map by SunMarc in 26949
* Device agnostic testing by vvvm23 in 25870
* Fix config silent copy in from_pretrained by patrickvonplaten in 27043
* [docs] Performance docs refactor p.2 by MKhalusova in 26791
* Add a default decoder_attention_mask for EncoderDecoderModel during training by hackyon in 26752
* Fix RoPE config validation for FalconConfig + various config typos by tomaarsen in 26929
* Skip-test by ArthurZucker in 27062
* Fix TypicalLogitsWarper tensor OOB indexing edge case by njhill in 26579
* [docstring] fix incorrect llama docstring: encoder -> decoder by ztjhz in 27071
* [DOCS] minor fixes in README.md by Akash190104 in 27048
* [`docs`] Add `MaskGenerationPipeline` in docs by younesbelkada in 27063
* 🌐 [i18n-ZH] Translate custom_models.md into Chinese by yyLeaves in 27065
* Hindi translation of pipeline_tutorial.md by AaryaBalwadkar in 26837
* Handle unsharded Llama2 model types in conversion script by coreyhu in 27069
* Bring back `set_epoch` for Accelerate-based dataloaders by muellerzr in 26850
* Bump`flash_attn` version to `2.1` by younesbelkada in 27079
* Remove unneeded prints in modeling_gpt_neox.py by younesbelkada in 27080
* Add-support for commit description by ArthurZucker in 26704
* [Llama FA2] Re-add _expand_attention_mask and clean a couple things by patrickvonplaten in 27074
* Correct docstrings and a typo in comments by lewis-yeung in 27047
* Save TB logs as part of push_to_hub by muellerzr in 27022
* Added huggingface emoji instead of the markdown format by shettyvarshaa in 27091
* [`T5Tokenizer`] Fix fast and extra tokens by ArthurZucker in 27085
* Revert "add exllamav2 arg" by ArthurZucker in 27102
* Add early stopping for Bark generation via logits processor by isaac-chung in 26675
* Provide alternative when warning on use_auth_token by Wauplin in 27105
* Fix no split modules underlying modules by SunMarc in 27090
* [`core`/ `gradient_checkpointing`] Refactor GC - part 2 by younesbelkada in 27073
* fix detr device map by SunMarc in 27089
* Added Telugu [te] translation for README.md in main by hakunamatata1997 in 27077
* translate transformers_agents.md to Chinese by jiaqiw09 in 27046
* Fix docstring and type hint for resize by daniilgaltsev in 27104
* [Typo fix] flag config in WANDB by SoyGema in 27130
* Fix slack report failing for doctest by ydshieh in 27042
* [`FA2`/ `Mistral`] Revert previous behavior with right padding + forward by younesbelkada in 27125
* Fix data2vec-audio note about attention mask by gau-nernst in 27116
* remove the obsolete code related to fairscale FSDP by statelesshz in 26651
* Fix some tests using `"common_voice"` by ydshieh in 27147
* [`tests` / `Quantization`] Fix bnb test by younesbelkada in 27145
* make tests of pytorch_example device agnostic by statelesshz in 27081
* Remove some Kosmos-2 `copied from` by ydshieh in 27149
* 🌐 [i18n-ZH] Translate serialization.md into Chinese by yyLeaves in 27076
* Translating `en/main_classes` folder docs to Japanese 🇯🇵 by rajveer43 in 26894
* Device agnostic trainer testing by statelesshz in 27131
* Fix: typos in README.md by THEFZNKHAN in 27154
* [KOSMOS-2] Update docs by NielsRogge in 27157
* deprecate function `get_default_device` in `tools/base.py` by statelesshz in 26774
* Remove broken links to s-JoL/Open-Llama by CSRessel in 27164
* [docstring] Fix docstring for AltCLIPTextConfig, AltCLIPVisionConfig and AltCLIPConfig by AksharGoyal in 27128
* [doctring] Fix docstring for BlipTextConfig, BlipVisionConfig by Hangsiin in 27173
* Disable CI runner check by ydshieh in 27170
* fix: Fix typical_p behaviour broken in recent change by njhill in 27165
* Trigger CI if `tiny_model_summary.json` is modified by ydshieh in 27175
* Shorten the conversation tests for speed + fixing position overflows by Rocketknight1 in 26960
* device agnostic pipelines testing by statelesshz in 27129
* Backward compatibility fix for the Conversation class by Rocketknight1 in 27176
* [`Quantization` / `tests` ] Fix bnb MPT test by younesbelkada in 27178
* Fix dropout in `StarCoder` by susnato in 27182
* translate traning.md to chinese by jiaqiw09 in 27122
* [docs] Update CPU/GPU inference docs by stevhliu in 26881
* device agnostic models testing by statelesshz in 27146
* Unify warning styles for better readability by oneonlee in 27184
* 🌐 [i18n-ZH] Translate tflite.md into Chinese by yyLeaves in 27134
* device agnostic fsdp testing by statelesshz in 27120
* Fix docstring get maskformer resize output image size by wesleylp in 27196
* Fix the typos and grammar mistakes in CONTRIBUTING.md. by THEFZNKHAN in 27193
* Fixing docstring in get_resize_output_image_size function by wesleylp in 27191
* added unsqueeze_dim to apply_rotary_pos_emb by ShashankMosaicML in 27117
* Added cache_block_outputs option to enable GPTQ for non-regular models by AlexKoff88 in 27032
* Add TensorFlow implementation of ConvNeXTv2 by neggles in 25558
* Fix docstring in get_oneformer_resize_output_image_size func by wesleylp in 27207
* improving TimmBackbone to support FrozenBatchNorm2d by rafaelpadilla in 27160
* Translate task summary to chinese by jiaqiw09 in 27180
* Fix CPU offload + disk offload tests by LysandreJik in 27204
* Enable split_batches through TrainingArguments by muellerzr in 26798
* support bf16 by etemadiamd in 25879
* Reproducible checkpoint for npu by statelesshz in 27208
* [`core` / `Quantization`] Fix for 8bit serialization tests by younesbelkada in 27234
Significant community contributions
The following contributors have made significant changes to the library over the last release:
* jungnerd
* 🌐 [i18n-KO] Translated `semantic_segmentation.md` to Korean (26515)
* statelesshz
* Extend Trainer to enable Ascend NPU to use the fused Adamw optimizer when training (26194)
* remove SharedDDP as it is deprecated (25702)
* remove the obsolete code related to fairscale FSDP (26651)
* make tests of pytorch_example device agnostic (27081)
* Device agnostic trainer testing (27131)
* deprecate function `get_default_device` in `tools/base.py` (26774)
* device agnostic pipelines testing (27129)
* device agnostic models testing (27146)
* device agnostic fsdp testing (27120)
* Reproducible checkpoint for npu (27208)
* sgugger
* Docstring check (26052)
* yyLeaves
* add zh translation for installation (26084)
* [i18n-ZH] Translated fast_tokenizers.md to Chinese (26910)
* 🌐 [i18n-ZH] Translate multilingual into Chinese (26935)
* 🌐 [i18n-ZH] Translate create_a_model.md into Chinese (27026)
* 🌐 [i18n-ZH] Translate custom_models.md into Chinese (27065)
* 🌐 [i18n-ZH] Translate serialization.md into Chinese (27076)
* 🌐 [i18n-ZH] Translate tflite.md into Chinese (27134)
* sinking-point
* In assisted decoding, pass model_kwargs to model's forward call (fix prepare_input_for_generation in all models) (25242)
* rajveer43
* add japanese documentation (26138)
* Translating `en/internal` folder docs to Japanese 🇯🇵 (26747)
* Refactor code part in documentation translated to japanese (26900)
* Translating `en/main_classes` folder docs to Japanese 🇯🇵 (26894)
* alvarorichard
* translation brazilian portuguese (26769)
* hakunamatata1997
* Added Telugu [te] translations (26828)
* Added Telugu [te] translation for README.md in main (27077)
* jiaqiw09
* Translate `pipeline_tutorial.md` to chinese (26954)
* translate `preprocessing.md` to Chinese (26955)
* translate transformers_agents.md to Chinese (27046)
* translate traning.md to chinese (27122)
* Translate task summary to chinese (27180)
* neggles
* Add TensorFlow implementation of ConvNeXTv2 (25558)