*Release date: 29 May, 2023*
<h3><b>Highlights:</a></b></h3>
* [**Multimodal**](https://maartengr.github.io/BERTopic/getting_started/multimodal/multimodal.html) Topic Modeling
* Train your topic modeling on text, images, or images and text!
* Use the `bertopic.backend.MultiModalBackend` to embed images, text, both or even caption images!
* [**Multi-Aspect**](https://maartengr.github.io/BERTopic/getting_started/multiaspect/multiaspect.html) Topic Modeling
* Create multiple topic representations simultaneously
* Improved [**Serialization**](https://maartengr.github.io/BERTopic/getting_started/serialization/serialization.html) options
* Push your model to the HuggingFace Hub with `.push_to_hf_hub`
* Safer, smaller and more flexible serialization options with `safetensors`
* Thanks to a great collaboration with HuggingFace and the authors of [BERTransfer](https://github.com/opinionscience/BERTransfer)!
* Added new embedding models
* OpenAI: `bertopic.backend.OpenAIBackend`
* Cohere: `bertopic.backend.CohereBackend`
* Added example of [summarizing topics](https://maartengr.github.io/BERTopic/getting_started/representation/representation.html#summarization) with OpenAI's GPT-models
* Added `nr_docs` and `diversity` parameters to OpenAI and Cohere representation models
* Use `custom_labels="Aspect1"` to use the aspect labels for visualizations instead
* Added cuML support for probability calculation in `.transform`
* Updated **topic embeddings**
* Centroids by default and c-TF-IDF weighted embeddings for `partial_fit` and `.update_topics`
* Added `exponential_backoff` parameter to `OpenAI` model
<h3><b>Fixes:</a></b></h3>
* Fixed custom prompt not working in `TextGeneration`
* Fixed [1142](https://github.com/MaartenGr/BERTopic/pull/1142)
* Add additional logic to handle cupy arrays by [metasyn](https://github.com/metasyn) in [#1179](https://github.com/MaartenGr/BERTopic/pull/1179)
* Fix hierarchy viz and handle any form of distance matrix by [elashrry](https://github.com/elashrry) in [#1173](https://github.com/MaartenGr/BERTopic/pull/1173)
* Updated languages list by [sam9111](https://github.com/sam9111) in [#1099](https://github.com/MaartenGr/BERTopic/pull/1099)
* Added level_scale argument to visualize_hierarchical_documents by [zilch42](https://github.com/zilch42) in [#1106](https://github.com/MaartenGr/BERTopic/pull/1106)
* Fix inconsistent naming by [rolanderdei](https://github.com/rolanderdei) in [#1073](https://github.com/MaartenGr/BERTopic/pull/1073)
<h3><b><a href="https://maartengr.github.io/BERTopic/getting_started/multimodal/multimodal.html">Multimodal Topic Modeling</a></b></h3>
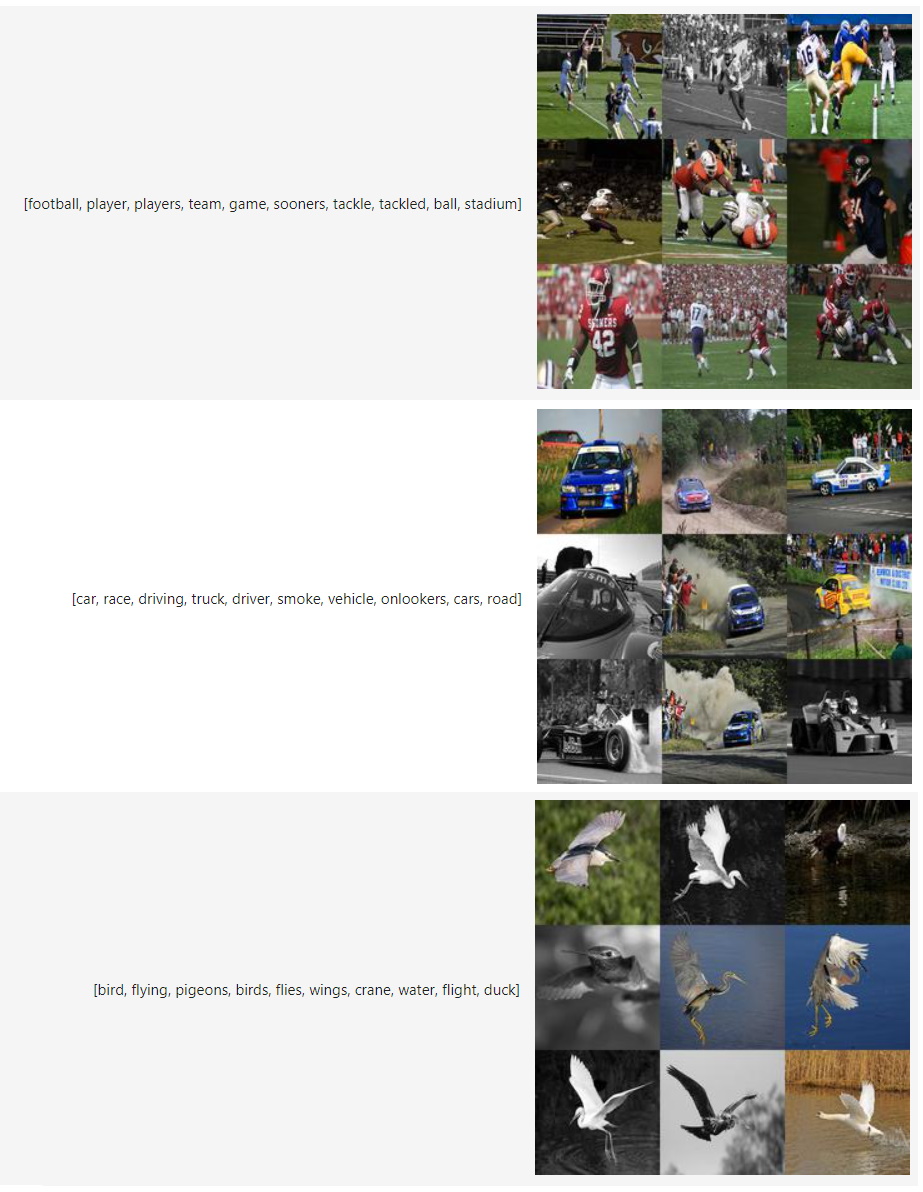
With v0.15, we can now perform multimodal topic modeling in BERTopic! The most basic example of multimodal topic modeling in BERTopic is when you have images that accompany your documents. This means that it is expected that each document has an image and vice versa. Instagram pictures, for example, almost always have some descriptions to them.
<figure markdown>

<figcaption></figcaption>
</figure>
In this example, we are going to use images from `flickr` that each have a caption associated to it:
python
NOTE: This requires the `datasets` package which you can
install with `pip install datasets`
from datasets import load_dataset
ds = load_dataset("maderix/flickr_bw_rgb")
images = ds["train"]["image"]
docs = ds["train"]["caption"]
The `docs` variable contains the captions for each image in `images`. We can now use these variables to run our multimodal example:
python
from bertopic import BERTopic
from bertopic.representation import VisualRepresentation
Additional ways of representing a topic
visual_model = VisualRepresentation()
Make sure to add the `visual_model` to a dictionary
representation_model = {
"Visual_Aspect": visual_model,
}
topic_model = BERTopic(representation_model=representation_model, verbose=True)
We can now access our image representations for each topic with `topic_model.topic_aspects_["Visual_Aspect"]`.
If you want an overview of the topic images together with their textual representations in jupyter, you can run the following:
python
import base64
from io import BytesIO
from IPython.display import HTML
def image_base64(im):
if isinstance(im, str):
im = get_thumbnail(im)
with BytesIO() as buffer:
im.save(buffer, 'jpeg')
return base64.b64encode(buffer.getvalue()).decode()
def image_formatter(im):
return f'<img src="data:image/jpeg;base64,{image_base64(im)}">'
Extract dataframe
df = topic_model.get_topic_info().drop("Representative_Docs", 1).drop("Name", 1)
Visualize the images
HTML(df.to_html(formatters={'Visual_Aspect': image_formatter}, escape=False))
<h3><b><a href="https://maartengr.github.io/BERTopic/getting_started/multiaspect/multiaspect.html">Multi-aspect Topic Modeling</a></b></h3>
In this new release, we introduce `multi-aspect topic modeling`! During the `.fit` or `.fit_transform` stages, you can now get multiple representations of a single topic. In practice, it works by generating and storing all kinds of different topic representations (see image below).
<figure markdown>

<figcaption></figcaption>
</figure>
The approach is rather straightforward. We might want to represent our topics using a `PartOfSpeech` representation model but we might also want to try out `KeyBERTInspired` and compare those representation models. We can do this as follows:
python
from bertopic.representation import KeyBERTInspired
from bertopic.representation import PartOfSpeech
from bertopic.representation import MaximalMarginalRelevance
from sklearn.datasets import fetch_20newsgroups
Documents to train on
docs = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))['data']
The main representation of a topic
main_representation = KeyBERTInspired()
Additional ways of representing a topic
aspect_model1 = PartOfSpeech("en_core_web_sm")
aspect_model2 = [KeyBERTInspired(top_n_words=30), MaximalMarginalRelevance(diversity=.5)]
Add all models together to be run in a single `fit`
representation_model = {
"Main": main_representation,
"Aspect1": aspect_model1,
"Aspect2": aspect_model2
}
topic_model = BERTopic(representation_model=representation_model).fit(docs)
As show above, to perform multi-aspect topic modeling, we make sure that `representation_model` is a dictionary where each representation model pipeline is defined.
The main pipeline, that is used in most visualization options, is defined with the `"Main"` key. All other aspects can be defined however you want. In the example above, the two additional aspects that we are interested in are defined as `"Aspect1"` and `"Aspect2"`.
After we have fitted our model, we can access all representations with `topic_model.get_topic_info()`:
<img src="getting_started/multiaspect/table.PNG">
<br>
As you can see, there are a number of different representations for our topics that we can inspect. All aspects are found in `topic_model.topic_aspects_`.
<h3><b><a href="https://maartengr.github.io/BERTopic/getting_started/serialization/serialization.html">Serialization</a></b></h3>
Saving, loading, and sharing a BERTopic model can be done in several ways. With this new release, it is now advised to go with `.safetensors` as that allows for a small, safe, and fast method for saving your BERTopic model. However, other formats, such as `.pickle` and pytorch `.bin` are also possible.
The methods are used as follows:
python
topic_model = BERTopic().fit(my_docs)
Method 1 - safetensors
embedding_model = "sentence-transformers/all-MiniLM-L6-v2"
topic_model.save("path/to/my/model_dir", serialization="safetensors", save_ctfidf=True, save_embedding_model=embedding_model)
Method 2 - pytorch
embedding_model = "sentence-transformers/all-MiniLM-L6-v2"
topic_model.save("path/to/my/model_dir", serialization="pytorch", save_ctfidf=True, save_embedding_model=embedding_model)
Method 3 - pickle
topic_model.save("my_model", serialization="pickle")
Saving the topic modeling with `.safetensors` or `pytorch` has a number of advantages:
* `.safetensors` is a relatively **safe format**
* The resulting model can be **very small** (often < 20MB>) since no sub-models need to be saved
* Although version control is important, there is a bit more **flexibility** with respect to specific versions of packages
* More easily used in **production**
* **Share** models with the HuggingFace Hub
<br><br>
<img src="getting_started/serialization/serialization.png">
<br><br>
The above image, a model trained on 100,000 documents, demonstrates the differences in sizes comparing `safetensors`, `pytorch`, and `pickle`. The difference in sizes can mostly be explained due to the efficient saving procedure and that the clustering and dimensionality reductions are not saved in safetensors/pytorch since inference can be done based on the topic embeddings.
<h3><b><a href="https://maartengr.github.io/BERTopic/getting_started/serialization/serialization.html#huggingFace-hub">HuggingFace Hub</a></b></h3>
When you have created a BERTopic model, you can easily share it with other through the HuggingFace Hub. First, you need to log in to your HuggingFace account:
python
from huggingface_hub import login
login()
When you have logged in to your HuggingFace account, you can save and upload the model as follows:
python
from bertopic import BERTopic
Train model
topic_model = BERTopic().fit(my_docs)
Push to HuggingFace Hub
topic_model.push_to_hf_hub(
repo_id="MaartenGr/BERTopic_ArXiv",
save_ctfidf=True
)
Load from HuggingFace
loaded_model = BERTopic.load("MaartenGr/BERTopic_ArXiv")