
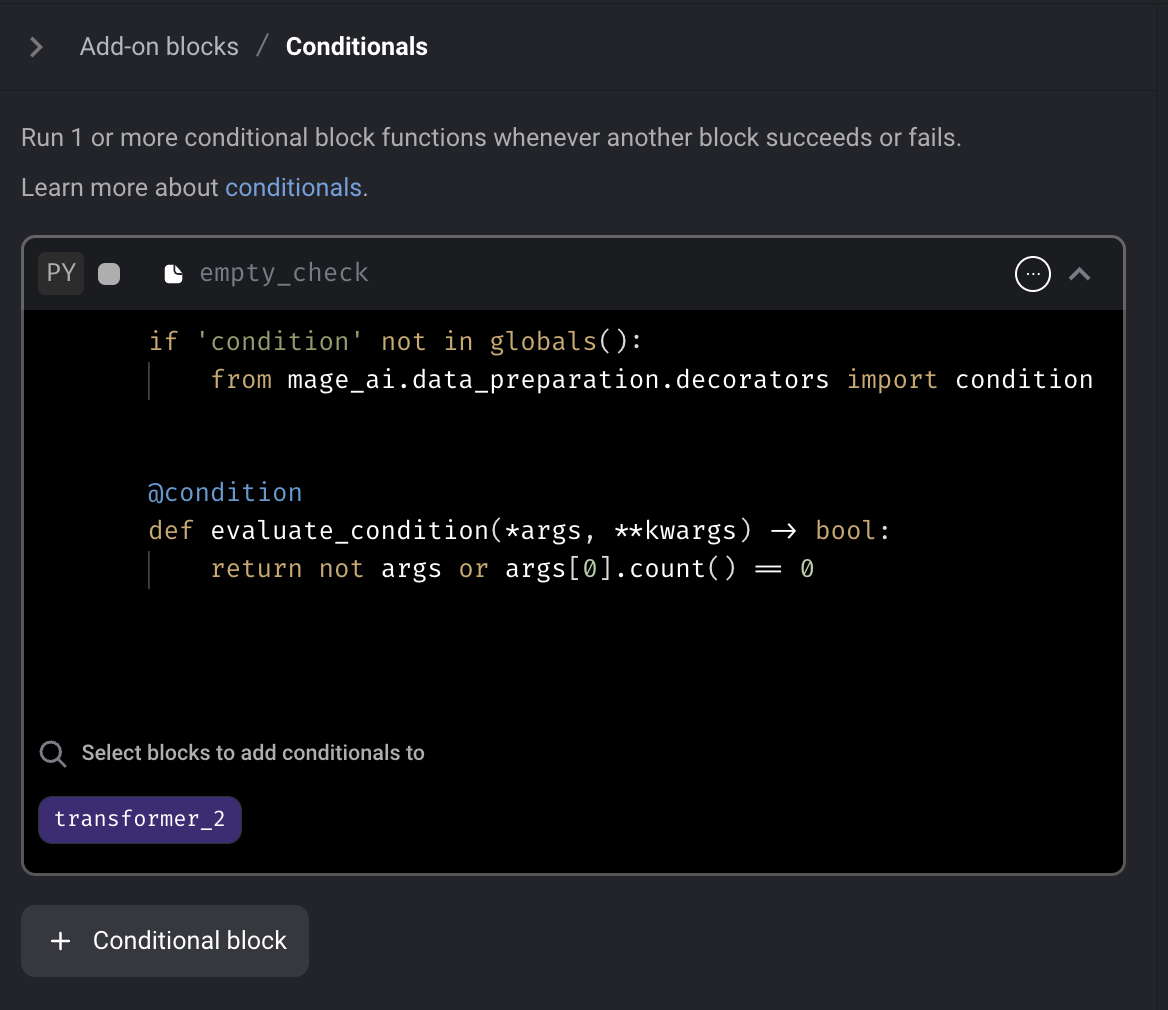
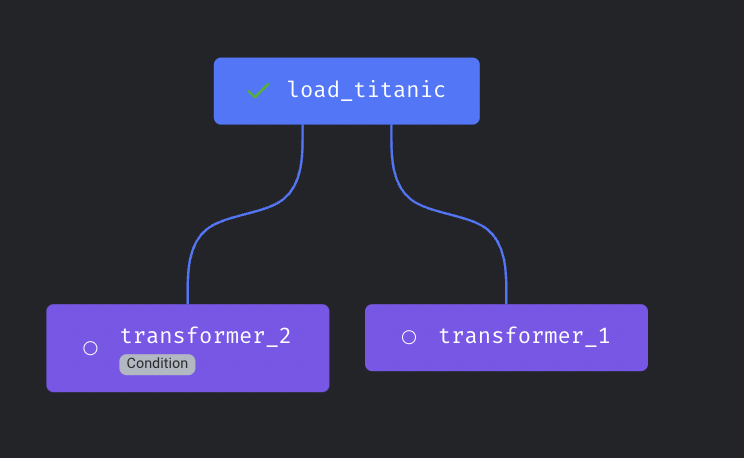
Conditional block
Add conditional block to Mage. The conditional block is an "Add-on" block that can be added to an existing block within a pipeline. If the conditional block evaluates as False, the parent block will not be executed.
Doc: https://docs.mage.ai/development/blocks/conditionals/overview
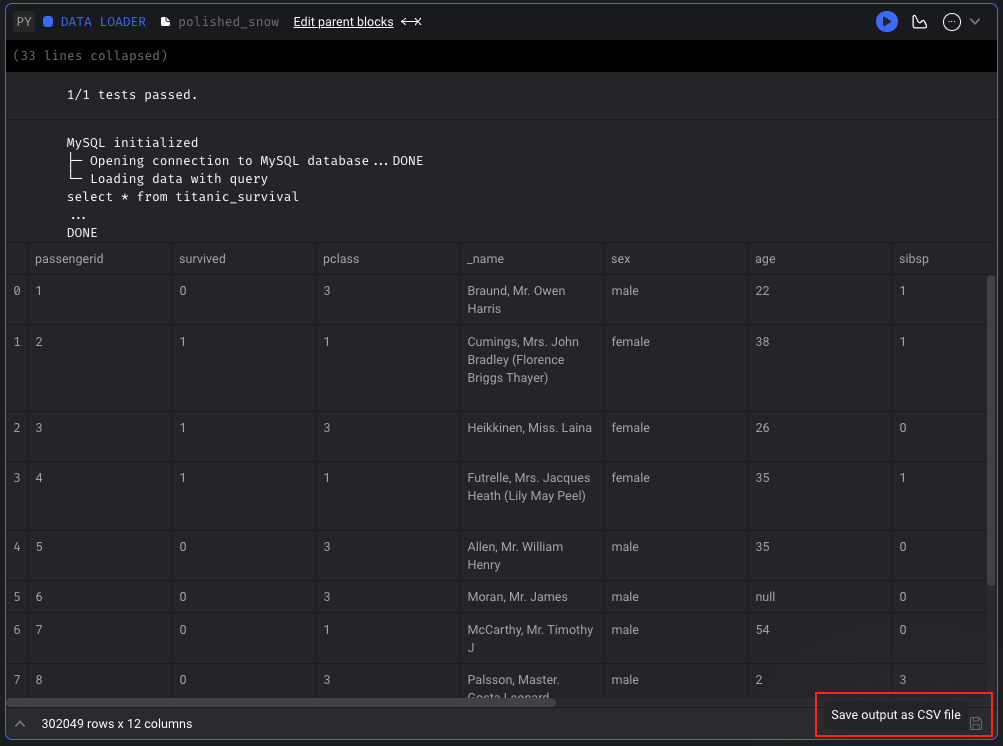
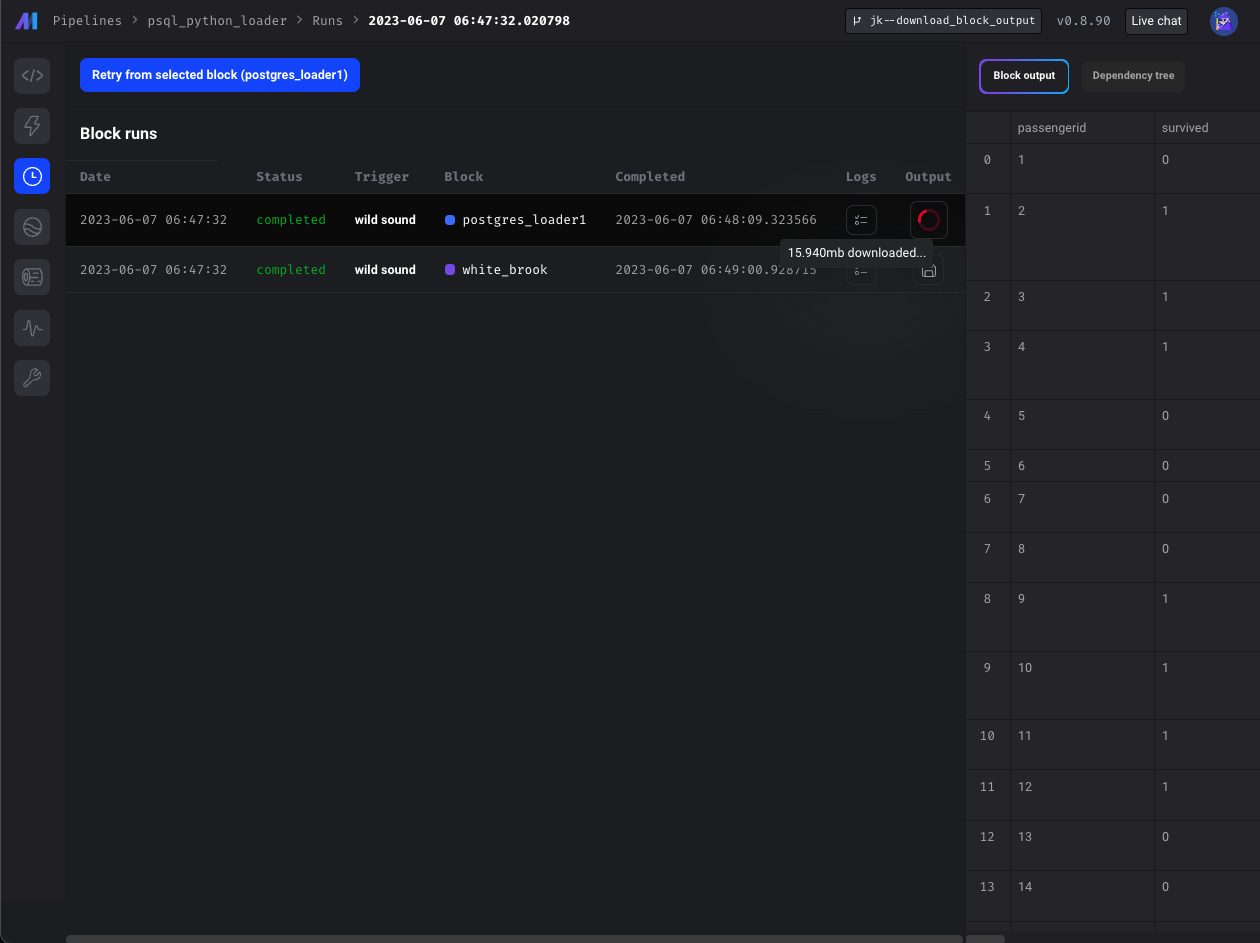
Download block output
For standard pipelines (not currently supported in integration or streaming pipelines), you can save the output of a block that has been run as a CSV file. You can save the block output in Pipeline Editor page or Block Runs page.
Doc: https://docs.mage.ai/orchestration/pipeline-runs/saving-block-output-as-csv
Customize Pipeline level spark config
Mage supports customizing Spark session for a pipeline by specifying the `spark_config` in the pipeline `metadata.yaml` file. The pipeline level `spark_config` will override the project level `spark_config` if specified.
Doc: https://docs.mage.ai/integrations/spark-pyspark#custom-spark-session-at-the-pipeline-level
Data integration pipeline
Oracle DB source
Doc: https://github.com/mage-ai/mage-ai/blob/master/mage_integrations/mage_integrations/sources/oracledb/README.md
Download file data in the API source
Doc: https://github.com/mage-ai/mage-ai/tree/master/mage_integrations/mage_integrations/sources/api
Personalize notification messages
Users can customize the notification templates of different channels (slack, email, etc.) in project metadata.yaml. Hare are the supported variables that can be interpolated in the message templates: `execution_time` , `pipeline_run_url` , `pipeline_schedule_id`, `pipeline_schedule_name`, `pipeline_uuid`
Example config in project's metadata.yaml
yaml
notification_config:
slack_config:
webhook_url: "{{ env_var('MAGE_SLACK_WEBHOOK_URL') }}"
message_templates:
failure:
details: >
Failure to execute pipeline {pipeline_run_url}.
Pipeline uuid: {pipeline_uuid}. Trigger name: {pipeline_schedule_name}.
Test custom message."

Doc: https://docs.mage.ai/production/observability/alerting-slack#customize-message-templates
Support **MSSQL and MySQL as the database engine**
Mage stores orchestration data, user data, and secrets data in a database. In addition to SQLite and Postgres, Mage supports using MSSQL and MySQL as the database engine now.
MSSQL docs:
- https://docs.mage.ai/production/databases/default#mssql
- https://docs.mage.ai/getting-started/setup#using-mssql-as-database
MySQL docs:
- https://docs.mage.ai/production/databases/default#mysql
- https://docs.mage.ai/getting-started/setup#using-mysql-as-database
Add MinIO and ****Wasabi**** support via S3 data loader block
Mage supports connecting to MinIO and Wasabi by specifying the `AWS_ENDPOINT` field in S3 config now.
Doc: https://docs.mage.ai/integrations/databases/S3#minio-support
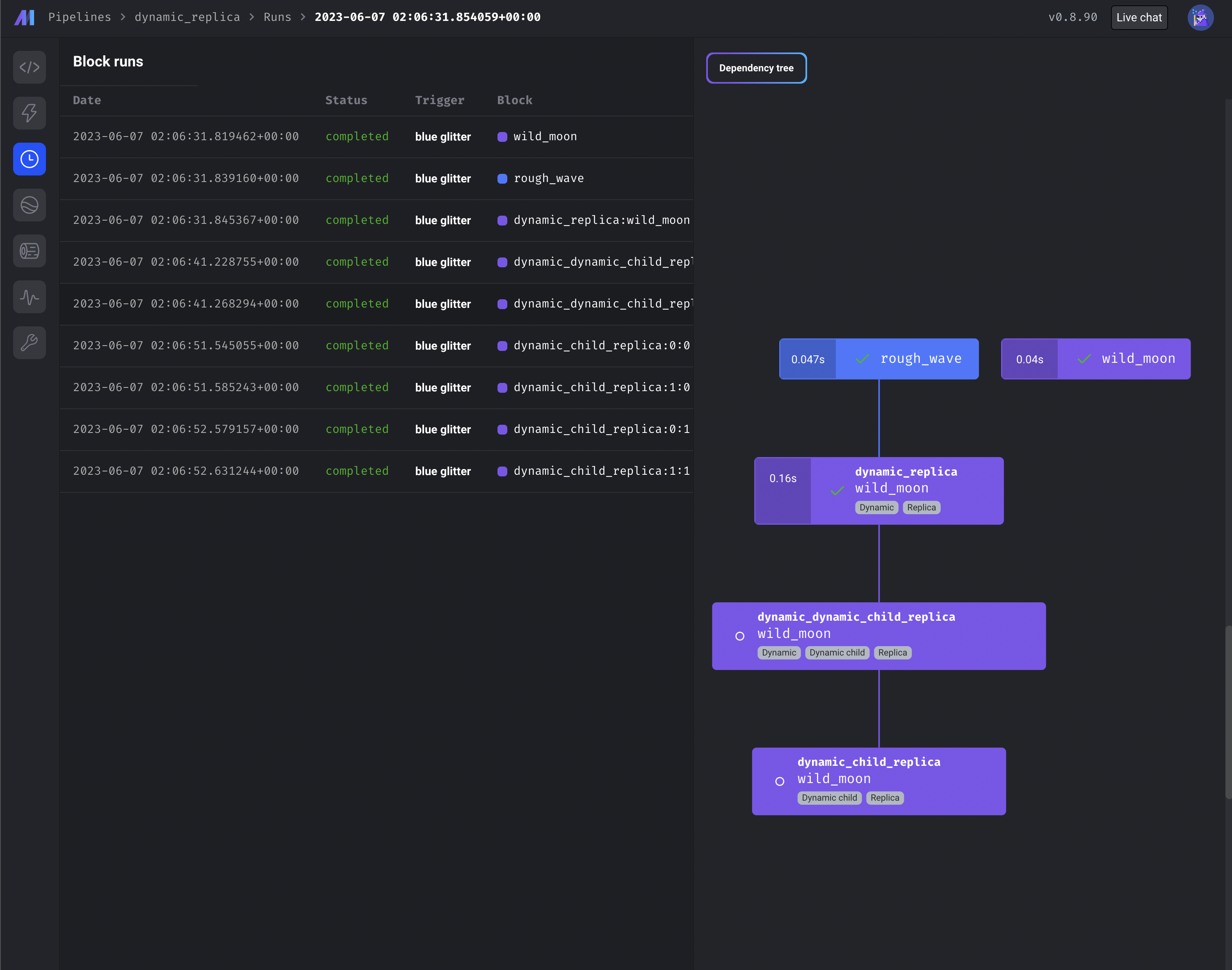
Use dynamic blocks with replica blocks
To maximize block reuse, you can use dynamic and replica blocks in combination.
- https://docs.mage.ai/design/blocks/dynamic-blocks
- https://docs.mage.ai/design/blocks/replicate-blocks
Other bug fixes & polish
- The command `CREATE SCHEMA IF NOT EXISTS` is not supported by MSSQL. Provided a default command in BaseSQL -> build_create_schema_command, and an overridden implementation in MSSQL -> build_create_schema_command containing compatible syntax. (Kudos to [gjvanvuuren](https://github.com/gjvanvuuren))
- Fix streaming pipeline `kwargs` passing so that RabbitMQ messages can be acknowledged correctly.
- Interpolate variables in streaming configs.
- Git integration: Create known hosts if it doesn't exist.
- Do not create duplicate triggers when DB query fails on checking existing triggers.
- Fix bug: when there are multiple downstream replica blocks, those blocks are not getting queued.
- Fix block uuid formatting for logs.
- Update WidgetPolicy to allow editing and creating widgets without authorization errors.
- Update sensor block to accept positional arguments.
- Fix variables for GCP Cloud Run executor.
- Fix MERGE command for Snowflake destination.
- Fix encoding issue of file upload.
- Always delete the temporary DBT profiles dir to prevent file browser performance degrade.