
Configure trigger in code
In addition to configuring triggers in UI, Mage also supports configuring triggers in code now. Create a `triggers.yaml` file under your pipeline folder and enter the triggers config. The triggers will automatically be synced to DB and trigger UI.
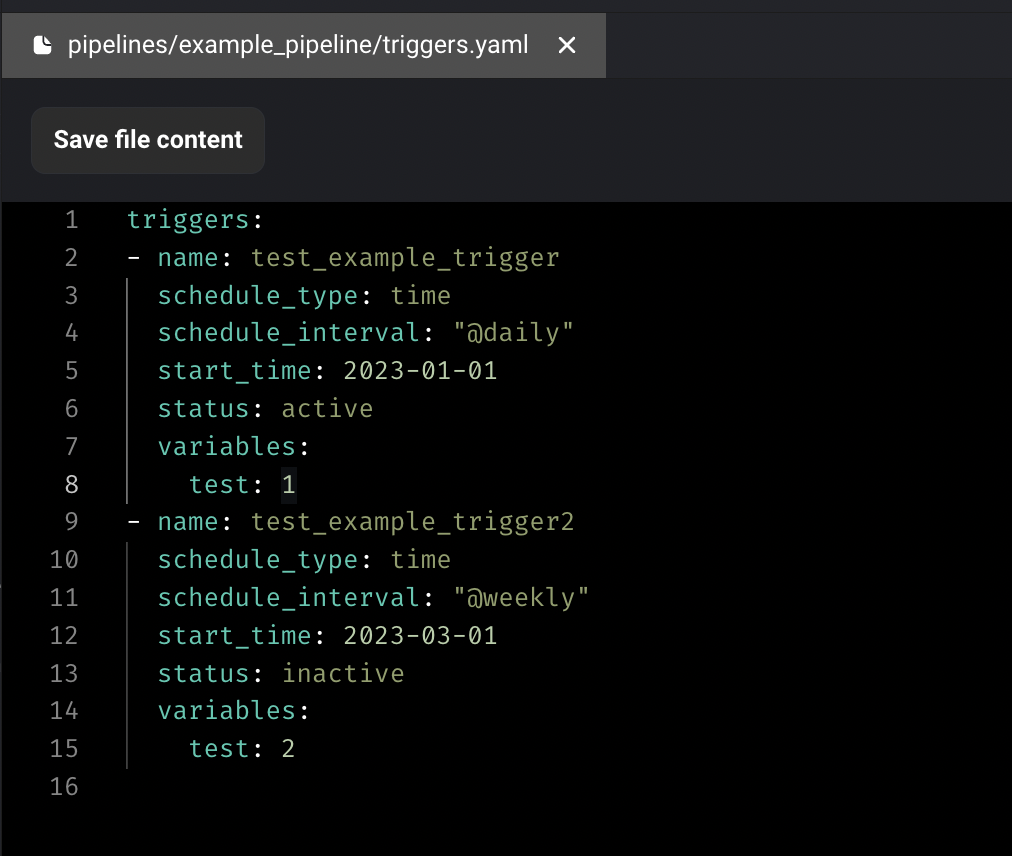
Doc: [https://docs.mage.ai/guides/triggers/configure-triggers-in-code](https://docs.mage.ai/guides/triggers/configure-triggers-in-code)
**Centralize server logger and add verbosity control**
Shout out to [Dhia Eddine Gharsallaoui](https://github.com/dhia-gharsallaoui) for his contribution of centralizing the server loggings and adding verbosity control. User can control the verbosity level of the server logging by setting the `SERVER_VERBOSITY` environment variables. For example, you can set `SERVER_VERBOSITY` environment variable to `ERROR` to only print out errors.
Doc: [https://docs.mage.ai/production/observability/logging#server-logging](https://docs.mage.ai/production/observability/logging#server-logging)
Customize resource for Kubernetes executor
User can customize the resource when using the Kubernetes executor now by adding the `executor_config` to the block config in pipeline’s `metadata.yaml`.
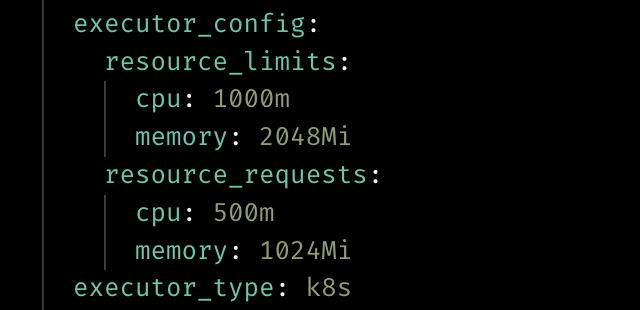
Doc: [https://docs.mage.ai/production/configuring-production-settings/compute-resource#kubernetes-executor](https://docs.mage.ai/production/configuring-production-settings/compute-resource#kubernetes-executor)
Data integration pipelines
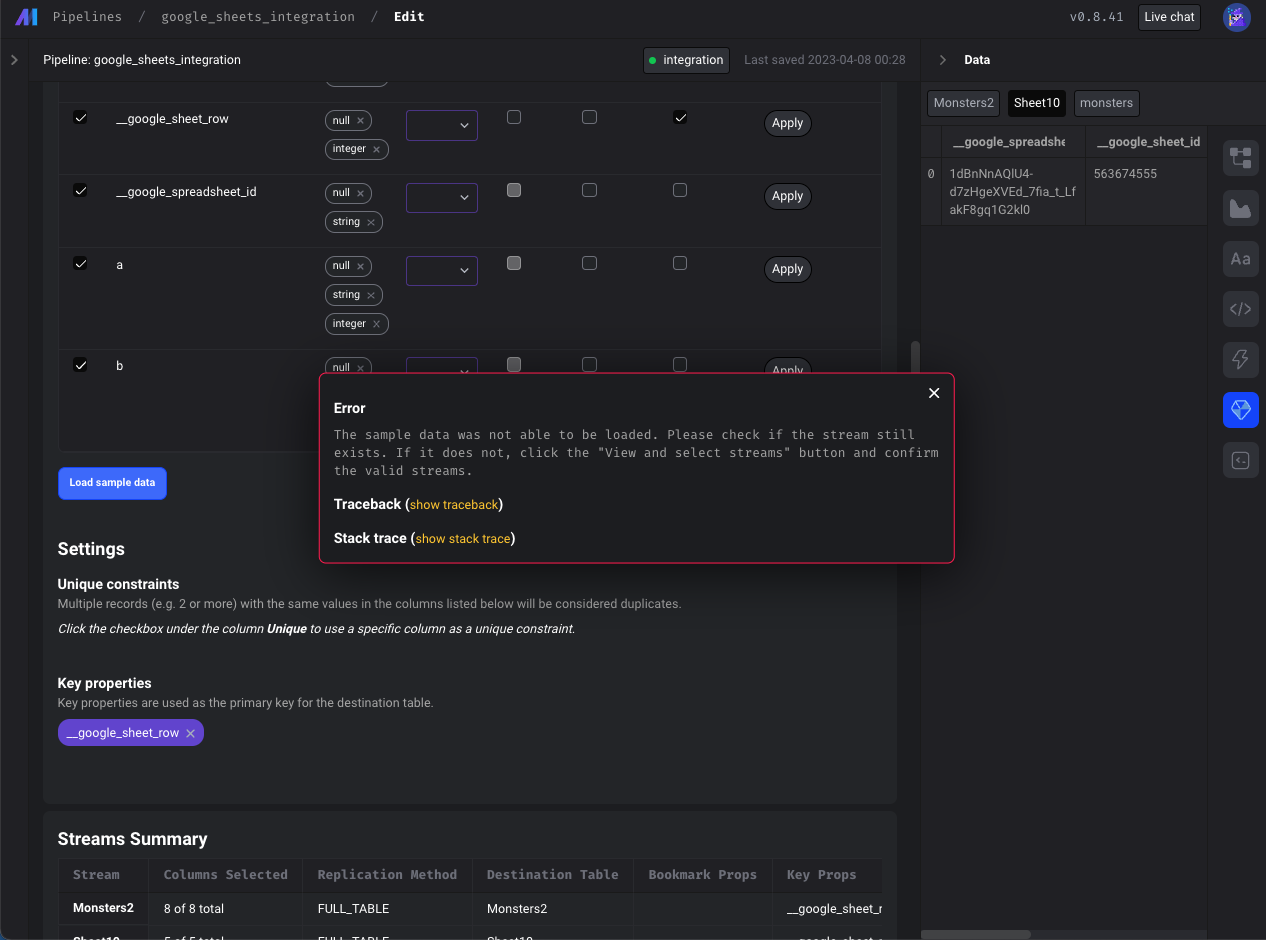
- **Google sheets source:** Fix loading sample data from Google Sheets
- **Postgres source:** Allow customizing the publication name for logical replication
- **Google search console source:** Support email field in google_search_console config
- **BigQuery destination:** Limit the number of subqueries in BigQuery query
- Show more descriptive error (instead of `{}`) when a stream that was previously selected may have been deleted or renamed. If a previously selected stream was deleted or renamed, it will still appear in the `SelectStreams` modal but will automatically be deselected and indicate that the stream is no longer available in red font. User needs to click "Confirm" to remove the deleted stream from the schema.
Terminal improvements
- Use named terminals instead of creating a unique terminal every time Mage connects to the terminal websocket.
- Update terminal for windows. Use `cmd` shell command for windows instead of bash. Allow users to overwrite the shell command with the `SHELL_COMMAND` environment variable.
- Support copy and pasting multiple commands in terminal at once.
- When changing the path in the terminal, don’t permanently change the path globally for all other processes.
- Show correct logs in terminal when installing requirements.txt.
DBT improvements
- Interpolate environment variables and secrets in DBT profile
Git improvements
- Update git to support multiple users
Postgres exporter improvements
- Support reordering columns when exporting a dataframe to Postgres
- Support specifying unique constraints when exporting the dataframe
python
with Postgres.with_config(ConfigFileLoader(config_path, config_profile)) as loader:
loader.export(
df,
schema_name,
table_name,
index=False,
if_exists='append',
allow_reserved_words=True,
unique_conflict_method='UPDATE',
unique_constraints=['col'],
)
Other bug fixes & polish
- Fix chart loading errors.
- Allow pipeline runs to be canceled from UI.
- Fix raw SQL block trying to export upstream python block.
- Don’t require metadata for dynamic blocks.
- When editing a file in the file editor, disable keyboard shortcuts for notebook pipeline blocks.
- Increase autosave interval from 5 to 10 seconds.
- Improve vertical navigation fixed scrolling.
- Allow users to force delete block files. When attempting to delete a block file with downstream dependencies, users can now override the safeguards in place and choose to delete the block regardless.
View full [Changelog](https://www.notion.so/mageai/What-s-new-7cc355e38e9c42839d23fdbef2dabd2c)