
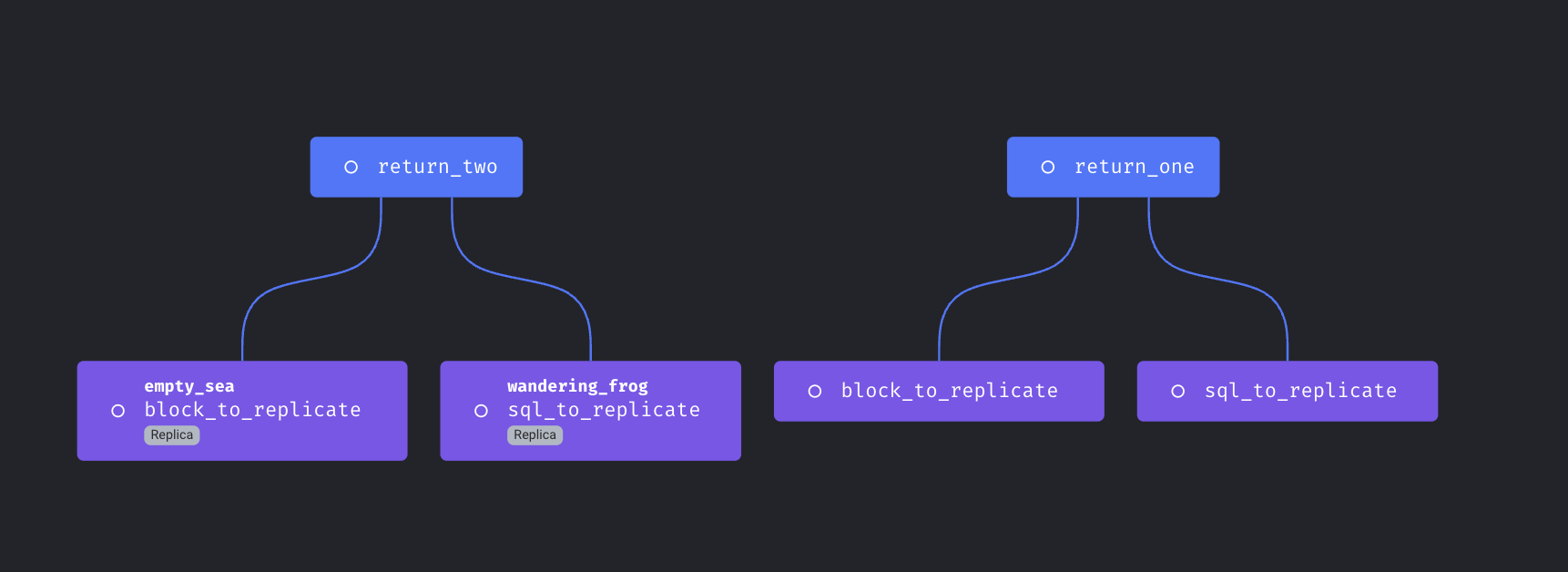
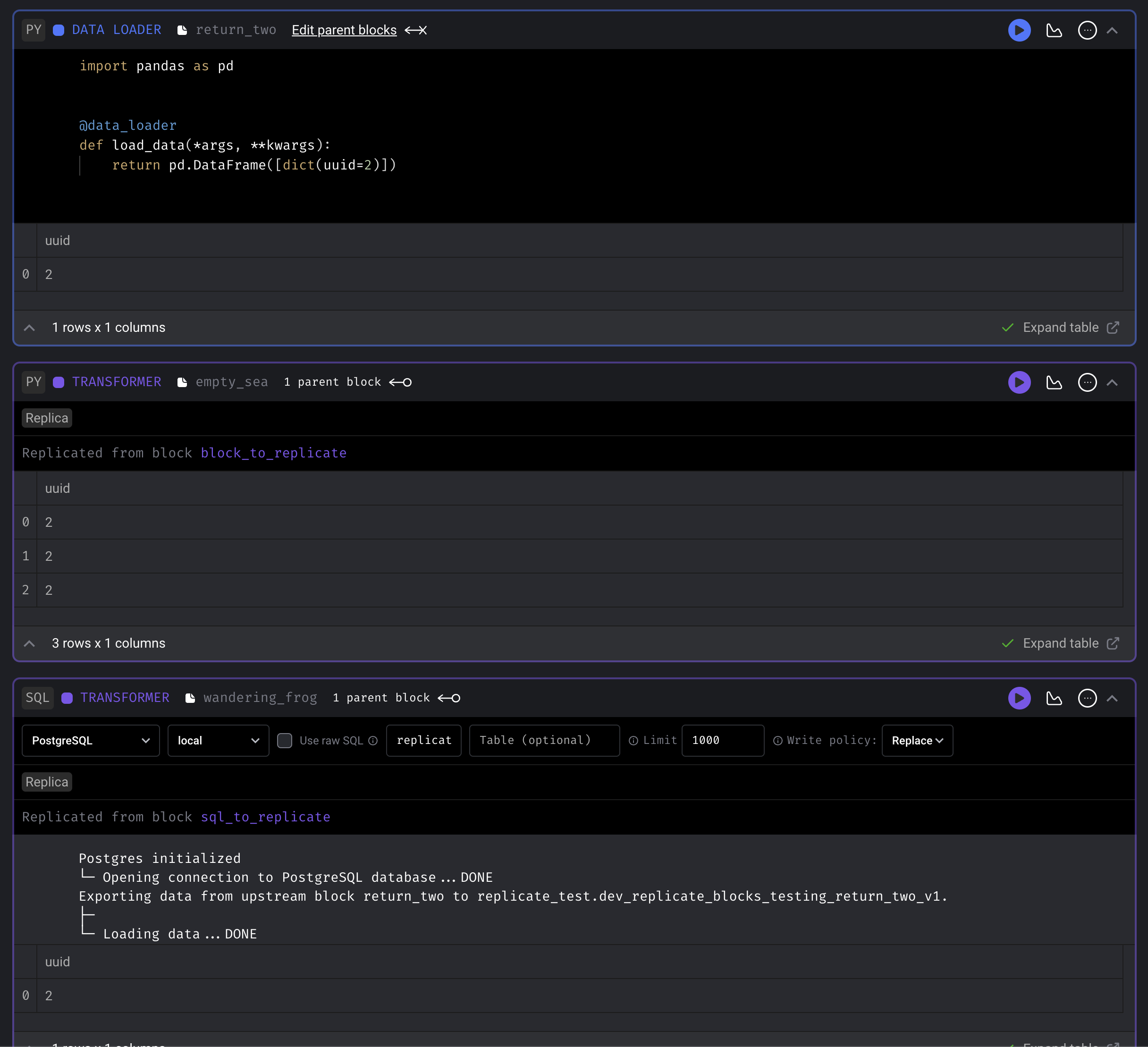
Replicate blocks
Support reusing same block multiple times in a single pipeline.
Doc: https://docs.mage.ai/design/blocks/replicate-blocks
Spark on Yarn
Support running Spark code on Yarn cluster with Mage.
Doc: https://docs.mage.ai/integrations/spark-pyspark#hadoop-and-yarn-cluster-for-spark
Customize retry config
Mage supports configuring automatic retry for block runs with the following ways
1. Add `retry_config` to project’s `metadata.yaml`. This `retry_config` will be applied to all block runs.
2. Add `retry_config` to the block config in pipeline’s `metadata.yaml`. The block level `retry_config` will override the global `retry_config`.
Example config:
yaml
retry_config:
Number of retry times
retries: 0
Initial delay before retry. If exponential_backoff is true,
the delay time is multiplied by 2 for the next retry
delay: 5
Maximum time between the first attempt and the last retry
max_delay: 60
Whether to use exponential backoff retry
exponential_backoff: true
Doc: https://docs.mage.ai/orchestration/pipeline-runs/retrying-block-runs#automatic-retry
DBT improvements
- When running DBT block with language YAML, interpolate and merge the user defined --vars in the block’s code into the variables that Mage automatically constructs
- Example block code of different formats
bash
--select demo/models --vars '{"demo_key": "demo_value", "date": 20230101}'
--select demo/models --vars {"demo_key":"demo_value","date":20230101}
--select demo/models --vars '{"global_var": {{ test_global_var }}, "env_var": {{ test_env_var }}}'
--select demo/models --vars {"refresh":{{page_refresh}},"env_var":{{env}}}
- Doc: https://docs.mage.ai/dbt/run-single-model#adding-variables-when-running-a-yaml-dbt-block
- Support `dbt_project.yml` custom project names and custom profile names that are different than the DBT folder name
- Allow user to configure block to run DBT snapshot
Dynamic SQL block
Support using dynamic child blocks for SQL blocks
Doc: https://docs.mage.ai/design/blocks/dynamic-blocks#dynamic-sql-blocks
Run blocks concurrently in separate containers on Azure
If your Mage app is deployed on Microsoft Azure with Mage’s **[terraform scripts](https://github.com/mage-ai/mage-ai-terraform-templates/tree/master/azure)**, you can choose to launch separate Azure container instances to execute blocks.
Doc: https://docs.mage.ai/production/configuring-production-settings/compute-resource#azure-container-instance-executor
Run the scheduler and the web server in separate containers or pods
- Run scheduler only: `mage start project_name --instance-type scheduler`
- Run web server only: `mage start project_name --instance-type web_server`
- web server can be run in multiple containers or pods
- Run both server and scheduler: `mage start project_name --instance-type server_and_scheduler`
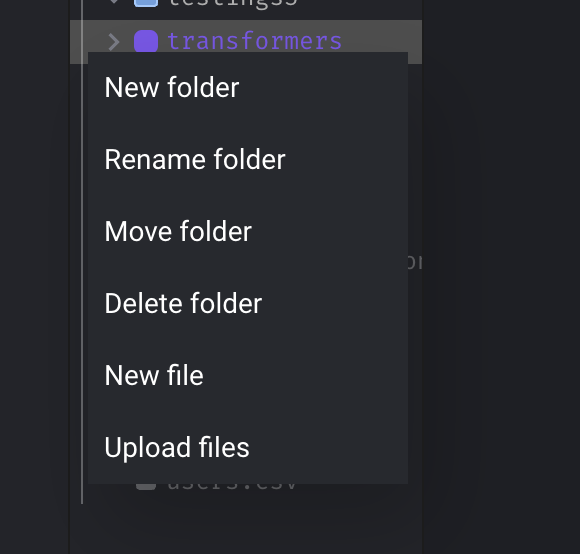
Support all operations on folder
Support “Add”, “Rename”, “Move”, “Delete” operations on folder.
Configure environments for triggers in code
Allow specifying `envs` value to apply triggers only in certain environments.
Example:
yaml
triggers:
- name: test_example_trigger_in_prod
schedule_type: time
schedule_interval: "daily"
start_time: 2023-01-01
status: active
envs:
- prod
- name: test_example_trigger_in_dev
schedule_type: time
schedule_interval: "hourly"
start_time: 2023-03-01
status: inactive
settings:
skip_if_previous_running: true
allow_blocks_to_fail: true
envs:
- dev
Doc: https://docs.mage.ai/guides/triggers/configure-triggers-in-code#create-and-configure-triggers
Replace current logs table with virtualized table for better UI performance
- Use virtual table to render logs so that loading thousands of rows won't slow down browser performance.
- Fix formatting of logs table rows when a log is selected (the log detail side panel would overly condense the main section, losing the place of which log you clicked).
- Pin logs page header and footer.
- Tested performance using Lighthouse Chrome browser extension, and performance increased 12 points.
Other bug fixes & polish
- Add indices to schedule models to speed up DB queries.
- “Too many open files issue”
- Check for "Too many open files" error on all pages calling "displayErrorFromReadResponse" util method (e.g. pipeline edit page), not just Pipelines Dashboard.
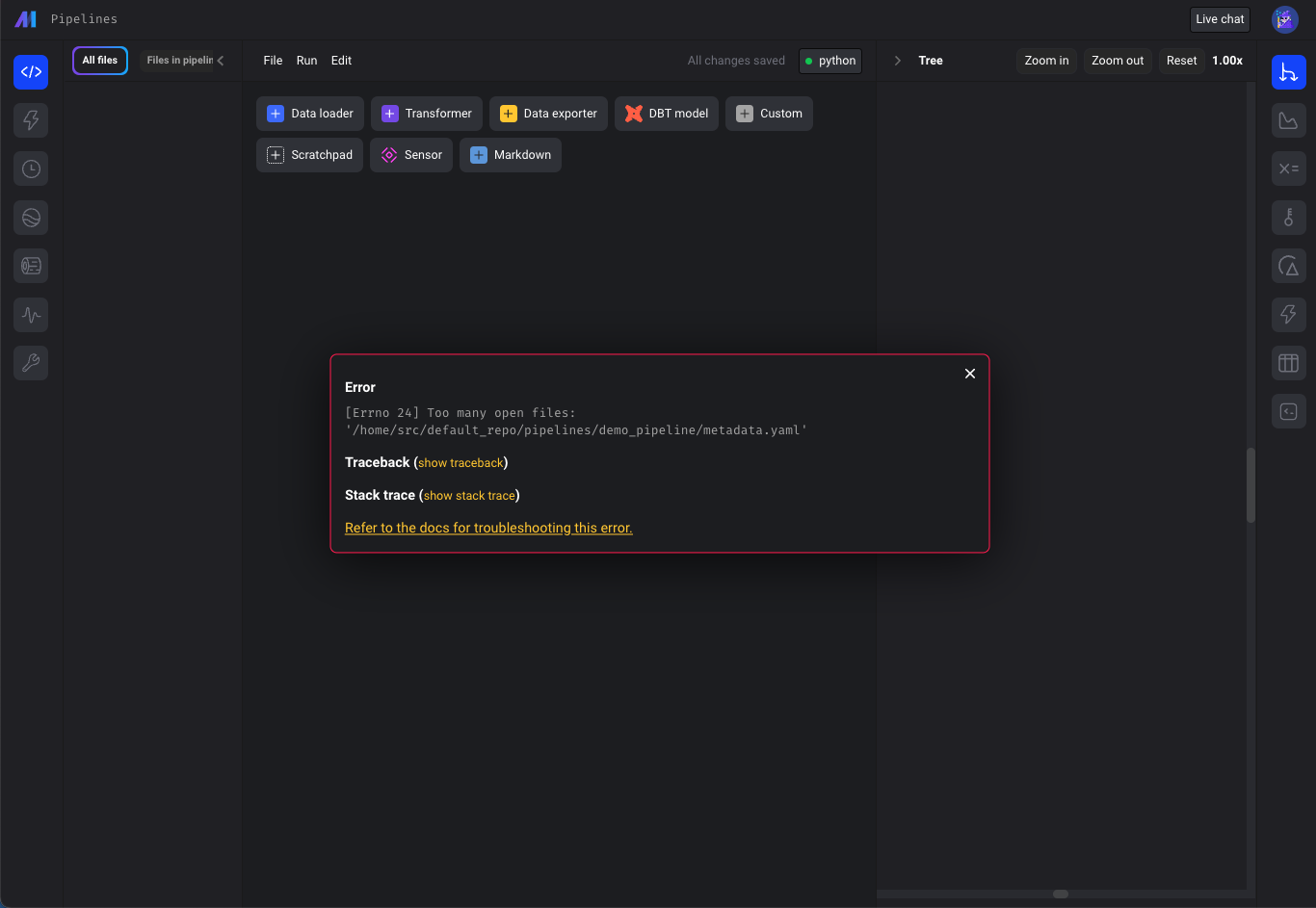
- Update terraform scripts to set the `ULIMIT_NO_FILE` environment variable to increase maximum number of open files in Mage deployed on AWS, GCP and Azure.
- Fix git_branch resource blocking page loads. The `git clone` command could cause the entire app to hang if the host wasn't added to known hosts. `git clone` command is updated to run as a separate process with the timeout, so it won't block the entire app if it's stuck.
- Fix bug: when adding a block in between blocks in pipeline with two separate root nodes, the downstream connections are removed.
- Fix DBT error: `KeyError: 'file_path'`. Check for `file_path` before calling `parse_attributes` method to avoid KeyError.
- Improve the coding experience when working with Snowflake data provider credentials. Allow more flexibility in Snowflake SQL block queries. Doc: https://docs.mage.ai/integrations/databases/Snowflake#methods-for-configuring-database-and-schema
- Pass parent block’s output and variables to its callback blocks.
- Fix missing input field and select field descriptions in charts.
- Fix bug: Missing values template chart doesn’t render.
- Convert `numpy.ndarray` to `list` if column type is list when fetching input variables for blocks.
- Fix runtime and global variables not available in the keyword arguments when executing block with upstream blocks from the edit pipeline page.
View full [Changelog](https://www.notion.so/What-s-new-7cc355e38e9c42839d23fdbef2dabd2c)